Clinical Quality Language Specification
1.5.3 - Release 1 Errata 2
Clinical Quality Language Specification
1.5.3 - Release 1 Errata 2
This page is part of the Clinical Quality Language Specification (v1.5.3: Normative - Normative) based on FHIR (HL7® FHIR® Standard) R4. This is the current published version. For a full list of available versions, see the Directory of published versions
| Page standards status: Normative | Maturity Level: N |
This chapter introduces the high-level syntax for the Clinical Quality Language focused on measure and decision support authors. This syntax provides a human-readable, yet precise mechanism for expressing logic in both the measurement and improvement domains of clinical quality.
The syntax, or structure, of CQL is built from several basic elements that are all classified as tokens. There are four different types of tokens present in CQL: symbols, such as + and *, keywords, such as define and from, literals, such as 5 and 'active', and identifiers, such as Person and "Inpatient Encounters".
Statements of CQL are built up by combining these basic elements, separated by whitespace (spaces, tabs, and returns), to produce language elements. The most basic of these language elements is an expression, which is any statement of CQL that returns a value.
Expressions are made up of terms (literals or identifiers) combined using operators. Operators can be symbolic, such as + and -, phrases such as and and exists, or named operators called functions, such as First() and AgeInYears().
At the highest level, CQL is organized around the concept of a library, which can be thought of as a container for artifact logic. Libraries contain declarations which specify the items the library contains. The most important of these declarations is the named expression, which is the basic unit of logic definition in CQL.
In the sections that follow, the various constructs introduced above will be discussed in more detail, beginning with the kinds of declarations that can be made in a CQL library, and then moving through the various ways that clinical information is referenced and queried within CQL, followed by an overview of the operators available in CQL, and ending with a detailed walkthrough of authoring specific quality artifacts using a running example.
It is important to keep in mind throughout the discussion that follows that CQL is a query language, which means that the statements of the language are really questions, formulated in terms of a data model that describes the available data. Depending on the use case, these questions will be evaluated in different ways to produce a response. For example, for decision support, the questions will likely be evaluated in the context of a specific patient and at some specific point in a workflow. For quality measurement, the questions will likely be evaluated for each of a set of patients in an overall population. However the evaluation occurs, the discussions in this chapter refer generally to the notion of an evaluation request that represents a request by some consumer to evaluate a CQL expression. This evaluation request generally includes the context of the evaluation (i.e. the inputs to the evaluation such as the patient and any parameter values), as well as a timestamp associated with when the evaluation request occurs.
Throughout the discussion, readers may find it helpful to refer to Appendix B – CQL Reference for more detailed discussion of particular concepts.
And as a final introductory note, CQL is designed to support two levels of usage. The first level focuses on the simplest possible expression of the most common use cases encountered in quality measurement and decision support, while the second level focuses on more advanced capabilities such as multi-source queries and user-defined functions. The first level is covered in this chapter, the Author's Guide, while the second level is covered in the next chapter, the Developer's Guide.
Constructs expressed within CQL are packaged in containers called libraries. Libraries provide a convenient unit for the definition, versioning, and distribution of logic. For simplicity, libraries in CQL correspond directly with a single file.
Libraries in CQL provide the overall packaging for CQL definitions. Each library allows a set of declarations to provide information about the library as well as to define constructs that will be available within the library.
Libraries can contain any or all of the following constructs:
| Construct | Description |
|---|---|
| library | Header information for the library, including the name and version, if any. |
| using | Data model information, specifying that the library may access types from the referenced data model. |
| include | Referenced library information, specifying that the library may access constructs defined in the referenced library. |
| codesystem | Codesystem information, specifying that logic within the library may reference the specified codesystem by the given name. |
| valueset | Valueset information, specifying that logic within the library may reference the specified valueset by the given name. |
| code | Code information, specifying that logic within the library may reference the specified code by the given name. |
| concept | Concept information, specifying that logic within the library may reference the specified concept by the given name. |
| parameter | Parameter information, specifying that the library expects parameters to be supplied by the evaluating environment. |
| context | Specifies the overall context, such as Patient or Practitioner, to be used in the statements that are declared in the library. Note that a library may have multiple context declarations, and that each context declaration establishes the context for the statements that follow, until the next context declaration is encountered. However, best practice is that each library should only contain a single context declaration as the first statement in the library. |
| define | The basic unit of logic within a library, a define statement introduces a named expression that can be referenced within the library, or by other libraries. |
| function | Libraries may also contain function definitions. A function in CQL is a named expression that is allowed to take any number of arguments, each of which has a name and a declared type. These are most often used as part of shared libraries. |
Table 2‑A - Constructs that CQL libraries can contain
A syntax diagram of a library containing all of the constructs can be seen here.
The following sections discuss these constructs in more detail.
The library declaration specifies both the name of the library and an optional version for the library. The library name is used as an identifier to reference the library from other CQL libraries, as well as eCQM and CDS artifacts. A library can have at most one library declaration.
The following example illustrates the library declaration:
library CMS153_CQM version '2'
The above declaration names the library with the identifier CMS153_CQM and specifies the version '2'.
A syntax diagram of the library declaration can be seen here.
A CQL library can reference zero or more data models with using declarations. These data models define the structures that can be used within retrieve expressions in the library.
For more information on how these data models are used, see the Retrieve section.
The following example illustrates the using declaration:
using QUICK
The above declaration specifies that the QUICK model will be used as the data model within the library. The QUICK data model will be used for the examples in this section unless specified otherwise.
If necessary, a version specifier can be provided to indicate which version of the data model should be used as shown below:
using QUICK version '0.3.0'
A syntax diagram of the using declaration can be seen here.
A CQL library can reference zero or more other CQL libraries with include declarations. Components defined within these included libraries can then be referenced within the library by name.
include CMS153_Common
Components defined in the CMS153_Common library can now be referenced using the library name. For example:
define "SexuallyActive":
exists (CMS153_Common."ConditionsIndicatingSexualActivity")
or exists (CMS153_Common."LaboratoryTestsIndicatingSexualActivity")
This expression references ConditionsIndicatingSexualActivity and LaboratoryTestsIndicatingSexualActivity defined in the CMS153_Common library.
The syntax used to reference these expressions is a qualified identifier consisting of two parts. The qualifier, CMS153_Common, and the identifier, ConditionsIndicatingSexualActivity, separated by a dot (.).
For more information on libraries, refer to the Using Libraries to Share Logic section.
The include declaration may optionally specify a version, meaning that a specific version of the library must be used:
include CMS153_Common version '2'
A more in-depth discussion of library versioning is provided in the Libraries section of the Developers guide.
In addition, the include declaration may optionally specify an assigned name using the called clause:
include CMS153_Common version '2' called Common
Components defined in the CMS153_Common library, version 2, can now be referenced using the assigned name of Common. For example:
define "SexuallyActive":
exists (Common."ConditionsIndicatingSexualActivity")
or exists (Common."LaboratoryTestsIndicatingSexualActivity")
A syntax diagram of the include declaration can be seen here.
A CQL library may contain zero or more named terminology declarations, including codesystems, valuesets, codes, and concepts, using the codesystem, valueset, code, and concept declarations.
These declarations specify a local name that represents a codesystem, valueset, code, or concept and can be used anywhere within the library where the terminology is expected.
The syntax diagrams of the codesystem definition,valueset definition, code definition and concept definition.
Consider the following valueset declaration:
valueset "Female Administrative Sex": 'urn:oid:2.16.840.1.113883.3.560.100.2'
This definition establishes the local name "Female Administrative Sex" as a reference to the external identifier for the valueset, more specifically, an Object Identifier (OID) in this particular case: 'urn:oid:2.16.840.1.113883.3.560.100.2'. The external identifier need not be an OID; instead, it may be a uniform resource identifier (URI), or any other identification system. CQL does not interpret the external id, it only specifies that the external identifier be a string that can be used to uniquely identify the valueset within the implementation environment.
This valueset definition can then be used within the library wherever a valueset can be used:
define "PatientIsFemale": Patient.gender in "Female Administrative Sex"
The above example defines the PatientIsFemale expression as true for patients whose gender is a code in the valueset identified by "Female Administrative Sex".
Note that the name of the valueset uses double quotes, unlike the string representation of the OID for the valueset, which uses single quotes. Single quotes are used to build arbitrary strings in CQL; double quotes are used to represent names of constructs such as valuesets and expression definitions.
Note also that the local name for a valueset is user-defined and not required to match the actual name of the valueset identified within the external valueset repository. However, when using external terminologies, authors should use the name of the terminology as defined externally to avoid introducing any potential confusion of meaning.
The following example illustrates a code system and a code declaration:
codesystem "SNOMED": 'http://snomed.info/sct'
code "Screening for Chlamydia trachomatis (procedure)":
'442487003' from "SNOMED" display 'Screening for Chlamydia trachomatis (procedure)'
This codesystem declaration in this example establishes the local name "SNOMED" as a reference to the external identifier for the codesystem, the URI "http://snomed.info/sct". The code declaration in this example establishes the local name "Screening for Chlamydia trachomatis (procedure)" as a reference to the code '442487003' from the "SNOMED" code system already defined.
For more information about terminologies as values within CQL, refer to the Clinical Values section.
A CQL library can define zero or more parameters. Each parameter is defined with the elements listed in the following table:
| Element | Description |
|---|---|
| Name | A unique identifier for the parameter within the library |
| Type | The type of the parameter – Note that the type is only required if no default value is provided. Otherwise, the type of the parameter is determined based on the default value. |
| Default Value | An optional default value for the parameter |
Table 2‑B - Elements that define a parameter
A syntax diagram of the parameter can be seen here.
The parameters defined in a library may be referenced by name in any expression within the library. When expressions in a CQL library are evaluated, the values for parameters are provided by the environment. For example, a library that defines criteria for a quality measure may define a parameter to represent the measurement period:
parameter MeasurementPeriod default Interval[@2013-01-01, @2014-01-01)
Note the syntax for the default here is called an interval selector and will be discussed in more detail in the section on Interval Values.
This parameter definition can now be referenced anywhere within the CQL library:
define "Patient16To23":
AgeInYearsAt(start of MeasurementPeriod) >= 16
and AgeInYearsAt(start of MeasurementPeriod) < 24
The above example defines the Patient16To23 expression as patients whose age at the start of the MeasurementPeriod was at least 16 and less than 24.
The default value for a parameter is optional, but if no default is provided, the parameter must include a type specifier:
parameter MeasurementPeriod Interval<DateTime>
If a parameter definition does not indicate a default value, a parameter value may be supplied by the evaluation environment, typically as part of the evaluation request. If the evaluation environment does not supply a parameter value, the parameter will be null.
In addition, because parameter defaults are part of the declaration, the expressions used to define them have the following restrictions applied:
. Parameter defaults cannot reference run-time data (i.e. they cannot contain Retrieve expressions) . Parameter defaults cannot reference expressions or functions defined in the current library . Parameter defaults cannot reference included libraries . Parameter defaults cannot perform terminology operations. For more information on terminology operations, see the Terminology Operators section. . Parameter defaults cannot reference other parameters
In other words, the value for the default of a parameter must be able to be calculated at compile-time.
The context declaration defines the scope of data available to statements within the language. Models define the available contexts, including at least one context named Unfiltered that indicates that statements are not restricted to a particular context. Consider the following simplified information model:
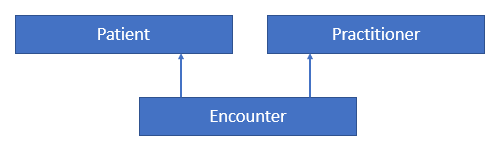
Figure 2-A - Simplified patient/practitioner information model
A patient and practitioner may both have any number of encounters. From the perspective of a patient (i.e. in patient context), only encounters for that particular patient are accessible. Likewise, from the perspective of a practitioner (i.e. in practitioner context), only encounters for that particular practitioner are accessible.
The following table lists some typical contexts:
| Context | Description |
|---|---|
| Patient | The Patient context specifies that expressions should be interpreted with reference to a single patient. |
| Practitioner | The Practitioner context specifies that expressions should be interpreted with reference to a single practitioner. |
| Unfiltered | The Unfiltered context indicates that expressions are not interpreted with reference to a particular context. |
Table 2‑C - Typical contexts for CQL
A syntax diagram of the context declaration can be seen here.
Depending on different needs, models may define any context appropriate to their use case, but should identify a default context that is used when authors do not declare a specific context.
When no context is specified in the library, and the model has not declared a default context, the default context is Unfiltered.
context Patient
define "Patient16To23AndFemale":
AgeInYearsAt(start of MeasurementPeriod) >= 16
and AgeInYearsAt(start of MeasurementPeriod) < 24
and Patient.gender in "Female Administrative Sex"
Because the context has been established as Patient, the expression has access to patient-specific concepts such as the AgeInYearsAt() operator and the Patient.gender attribute. Note that the attributes available in the Patient context are defined by the data model in use.
A library may contain zero or more context statements, with each context statement establishing the context for subsequent statements in the library.
Effectively, the statement context Patient defines an expression named Patient that returns the patient data for the current patient, as well as restricts the information that will be returned from a retrieve to a single patient, as opposed to all patients.
As another example, consider a Practitioner context:
context Practitioner
define "Encounters":
["Encounter": "Inpatient Encounter"]
The above definition results in all the encounters for a particular practitioner. For more information on context, refer to the Retrieve Context discussion below.
A CQL Library can contain zero or more define statements describing named expressions that can be referenced either from other expressions within the same library or by containing quality and decision support artifacts.
The following example illustrates a simple define statement:
define "InpatientEncounters":
[Encounter: "Inpatient"] E
where E.length <= 120 days
and E.period ends during MeasurementPeriod
This example defines the InpatientEncounters expression as Encounter events whose code is in the "Inpatient" valueset, whose length is less than or equal to 120 days, and whose period ended (i.e. patient was discharged) during MeasurementPeriod.
Note that the use of terms like Encounter, length, and period, as well as which code attribute is used to compare with the valueset, are defined by the data model being used within the library; they are not defined by CQL.
For more information on the use of define statements, refer to the Using Define Statements section.
The retrieve expression is the central construct for accessing clinical information within CQL. The result of a retrieve is always a list of some type of clinical data, based on the type described by the retrieve and the context (such as Patient, Practitioner, or Unfiltered) in which the retrieve is evaluated.
The retrieve in CQL has two main parts: first, the type part, which identifies the type of data that is to be retrieved; and second, the filter part, which optionally provides filtering information based on specific types of filters common to most clinical data.
A syntax diagram of the retrieve expression can be seen here.
Note that the retrieve only introduces data into an expression; operations for further filtering, shaping, computation, and sorting will be discussed in later sections.
The retrieve expression is a reflection of the idea that clinical data in general can be viewed as clinical statements of some type as defined by the model. The type of the clinical statement determines the structure of the data that is returned by the retrieve, as well as the semantics of the data involved.
The type may be a general category, such as a Condition, Procedure, or Encounter, or a more specific instance such as an ImagingProcedure or a LaboratoryTest. The data model defines the available types that may be referenced by a retrieve.
In the simplest case, a retrieve specifies only the type of data to be retrieved. For example:
[Encounter]
Assuming the default context of Patient, this example retrieves all Encounter statements for a patient.
In addition to describing the type of clinical statements, the retrieve expression allows the results to be filtered using terminology, including valuesets, code systems, or by specifying a single code. The use of codes within clinical data is ubiquitous, and most clinical statements have at least one code-valued attribute. In addition, there is typically a “primary” code-valued attribute for each type of clinical statement. This primary code is used to drive the terminology filter. For example:
[Condition: "Acute Pharyngitis"]
This example requests only those Conditions whose primary code attribute is a code from the valueset identified by "Acute Pharyngitis". The attribute used as the primary code attribute is defined by the data model being used.
In addition, the retrieve expression allows the filtering attribute name to be specified:
[Condition: severity in "Acute Severity"]
This requests clinical statements that assert the presence of a condition with a severity in the "Acute Severity" valueset.
Note that the terminology reference "Acute Severity" in the above examples is a valueset, but it could also be a code system, a concept, or a specific code:
codesystem "SNOMED": 'http://snomed.info/sct'
code "Acute Pharyngitis Code":
'363746003' from "SNOMED" display 'Acute pharyngitis (disorder)'
define "Get Condition from Code Declaration":
[Condition: "Acute Pharyngitis Code"]
define "Get Condition from CodeSystem Declaration":
[Condition: "SNOMED"]
The "Get Condition from Code Declaration" expression returns conditions for the patient where the code is equivalent to the "Acute Pharyngitis Code" code. The "Get Condition from CodeSystem Declaration" expression returns conditions for the patient where the code is some code in the "SNOMED" code system.
When the primary code attribute is used (i.e. no filtering attribute name is specified in the retrieve), the retrieve uses the membership operator (in) if the terminology target is a valueset or code system, and the equivalent operator (~) otherwise. For more information about using the equivalent operator with terminology, refer to the Code section. For more information about using the membership operator with terminology, refer to the Terminology Operators section.
When the code path is specified, the code comparison operation can be specified as well:
codesystem "SNOMED": 'http://snomed.info/sct'
code "Acute Pharyngitis Code":
'363746003' from "SNOMED" display 'Acute pharyngitis (disorder)'
define "Get Condition from Code Declaration":
[Condition: code ~ "Acute Pharyngitis Code"]
define "Get Condition from CodeSystem Declaration":
[Condition: code in "SNOMED"]
define "Get Condition from Exact Match To Code":
[Condition: code = "Acute Pharyngitis Code"]
Note the last example here is using the equality operator (=) to indicate the terminology match should be exact (meaning that it will consider code system version and display as well as the code and system). Equality, equivalence, and membership are the only allowed terminology comparison operators within a retrieve.
Within the Patient context, the results of any given retrieve will always be scoped to a single patient, as determined by the environment. For example, in a quality measure evaluation environment, the Patient context may be the current patient being considered. In a clinical decision support environment, the Patient context would be the patient for which guidance is being sought.
By contrast, if the Unfiltered context is used, the results of any given retrieve will not be limited to a particular context. For example:
[Condition: "Acute Pharyngitis"] C where C.onsetDateTime during MeasurementPeriod
When evaluated within the Patient context, the above example returns "Acute Pharyngitis" conditions that onset during MeasurementPeriod for the current patient only. In the Unfiltered context, this example returns all "Acute Pharyngitis" conditions that onset during MeasurementPeriod, regardless of patient.
As another example, consider the set of encounters:
[Encounter: "Inpatient"]
Depending on the context the retrieve above will return:
Consider the figure below:
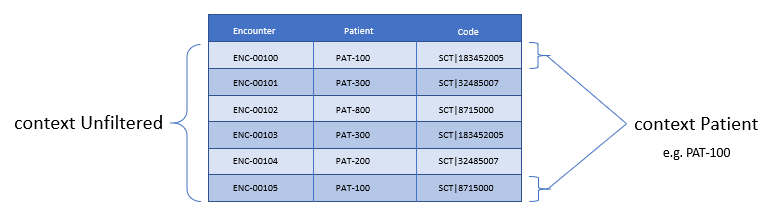
Figure 2‑B - Unfiltered vs Patient context
Because context is associated with each declaration, it is possible for expressions defined in a particular context to reference expressions defined in the Unfiltered context and vice versa. Best practice is for each library to have expressions in only one context, and for that context declaration to be the first declaration in the library.
Note that it is not legal for an expression in one specified context to reference an expression in another specified context. This is because there must be a way to relate cross-context queries, which is only possible in the Unfiltered context, or through the use of a cross-context retrieve.
In an Unfiltered context, a reference to a specified context expression (such as Patient) results in the execution of that expression for each patient in the unfiltered context, and the implementation environment combines the results.
If the result type of an expression in a specific context is not a list, the result of accessing it from an Unfiltered context will be a list with elements of the type of the expression. For example:
context Patient
define "InInitialPopulation":
AgeInYearsAt(@2013-01-01) >= 16 and AgeInYearsAt(@2013-01-01) < 24
context Unfiltered
define "InitialPopulationCount":
Count(InInitialPopulation IP where IP is true)
In the above example, the InitialPopulationCount expression returns the number of patients for which the InInitialPopulation expression evaluated to true.
If the result type of the Patient context expression is a list, the result will be a list of the same type, but with the results of the evaluation for each patient in the unfiltered context flattened into a single list.
In a specific context (such as Patient), a reference to an Unfiltered context expression results in the evaluation of the Unfiltered context expression, and the result type is unaffected.
In some cases, measures or decision support artifacts may need to access data for a related person, such as the mother’s record from an infant’s context. For information on how to do this in CQL, refer to Related Context Retrieves.
Beyond the retrieve expression, CQL provides a query construct that allows the results of retrieves to be further filtered, shaped, and extended to enable the expression of arbitrary clinical logic that can be used in quality and decision support artifacts.
Although similar to a retrieve in that a query will typically result in a list of patient information, a query is a more general construct than a retrieve. Retrieves are by design restricted to a particular set of criteria that are commonly used when referencing clinical information, and specifically constructed to allow implementations to easily build data access layers suitable for use with CQL. For more information on the design of the retrieve construct, refer to Clinical Data Retrieval in Quality Artifacts.
The query construct has a primary source and four main clauses that each allow for different types of operations to be performed:
| Clause | Operation |
|---|---|
| Relationship (with/without) | Allows relationships between the primary source and other clinical information to be used to filter the result. |
| Where | The where clause allows conditions to be expressed that filter the result to only the information that meets the condition. |
| Return | The return clause allows the result set to be shaped as needed, removing elements, or including new calculated values. |
| Sort | The sort clause allows the result set to be ordered according to any criteria as needed. |
Table 2‑D - Four main clauses for a query construct
Each of these clauses will be discussed in more detail in the following sections.
A query construct begins by introducing an alias for the primary source:
[Encounter: "Inpatient"] E
The primary source for this query is the retrieve expression +++[+++Encounter: "Inpatient"], and the alias is E. Subsequent clauses in the query must reference elements of this source by using this alias.
Although the alias in this example is a single-letter abbreviation, E, it could also be a longer abbreviation:
[Encounter: "Inpatient"] Enc
Note that alias names, as with all language constructs, may be the subject of language conventions. The Formatting Conventions section defines a very general set of formatting conventions for use with Clinical Quality Languages. Within specific domains, institutions or stakeholders may create additional conventions and style guides appropriate to their domains.
The where clause allows the results of the query to be filtered by a condition that is evaluated for each element of the query being filtered. If the condition evaluates to true for the element being tested, that element is included in the result. Otherwise, the element is excluded from the resulting list.
A syntax diagram of a where clause can be seen here.
For example:
[Encounter: "Inpatient"] E
where duration in days of E.period >= 120
The alias E is used to access the period attribute of each encounter in the primary source. The filter condition tests whether the duration of that range is at least 120 days.
The condition of a where clause is allowed to contain any arbitrary combination of operations of CQL, so long as the overall result of the condition is boolean-valued. For example, the following where clause includes multiple conditions on different attributes of the source:
[CommunicationRequest] C
where C.mode = 'ordered'
and C.sender.role = 'nurse'
and C.recipient.role = 'doctor'
and C.indication in "Fever"
Note that because CQL uses three-valued logic, the result of evaluating any given boolean-valued condition may be unknown (null). For example, if the list of inpatient encounters from the first example contains some elements whose period attribute is null, the result of the condition for that element will not be false, but null, indicating that it is not known whether or not the duration of the encounter was at least 120 days. For the purposes of evaluating a filter, only elements where the condition evaluates to true are included in the result, effectively ignoring the entries for which the logical expression evaluates to null. For more discussion on three-valued logic, see the section on Missing Information in the Author's Guide, as well as the section on Nullological Operators in the Developer's guide.
The return clause of a CQL query allows the results of the query to be shaped. In most cases, the results of a query will be of the same type as the primary source of the query. However, some scenarios require only specific elements be extracted, or computations on the data involved in each element be performed. The return clause enables this type of query.
A syntax diagram of a return clause can be seen here.
For example:
[Encounter: "Inpatient"] E
return Tuple { id: E.identifier, lengthOfStay: duration in days of E.period }
This example returns a list of tuples (structured values), one for each inpatient encounter performed, where each tuple consists of the id of the encounter as well as a lengthOfStay element, whose value is calculated by taking the duration of the period for the encounter. Tuples are discussed in detail in later sections. For more information on Tuples, see Structured Values (Tuples).
By default, a query returns a list of distinct results, suppressing duplicates. To include duplicates, use the all keyword in the return clause. For example, the following will return a list of the lengths of stay for each Encounter:
[Encounter: "Inpatient"] E
return E.lengthOfStay
If two encounters have the same value for lengthOfStay, that value will only appear once in the result unless the all keyword is used:
[Encounter: "Inpatient"] E
return all E.lengthOfStay
CQL queries can sort results in any order using the sort by clause.
A syntax diagram of a sort clause can be seen here.
For example:
[Encounter: "Inpatient"] E sort by start of period
This example returns inpatient encounters, sorted by the start of the encounter period.
Results can be sorted ascending or descending using the asc (ascending) or desc (descending) keywords:
[Encounter: "Inpatient"] E sort by start of period desc
If no ascending or descending specifier is provided, the order is ascending.
Calculated values can also be used to determine the sort:
[Encounter: "Inpatient"] E
return Tuple { id: E.identifier, lengthOfStay: duration in days of E.period }
sort by lengthOfStay
Note that the properties that can be specified within the sort clause are determined by the result type of the query. In the above example, [id]#lengthOfStay# can be referenced because it is introduced in the return clause. Because the sort applies after the query results have been determined, alias references are neither required nor allowed in the sort.
If no sort clause is provided, the order of the result is unprescribed and is implementation specific.
The sort clause may include multiple attributes, each with their own sort order:
[Encounter: "Inpatient"] E sort by start of period desc, identifier asc
Sorting is performed in the order in which the attributes are defined in the sort clause, so this example sorts by period descending, then by identifier ascending.
When the sort elements do not provide a unique ordering (i.e. there is a possibility of duplicate sort values in the result), the order of duplicates is unspecified.
A query may only contain a single sort clause, and it must always appear last in the query.
When the data being sorted includes nulls, they are considered lower than any non-null value, meaning they will appear at the beginning of the list when the data is sorted ascending, and at the end of the list when the data is sorted descending.
Within the expressions of a sort clause, the iteration accessor $this may be used to access the current iteration element, and $index may be used to access the 0-based index of the current iteration.
In addition to filtering by conditions, some scenarios need to be able to filter based on relationships to other sources. The CQL with and without clauses provide this capability. For the examples in this section, consider the following simple information model:
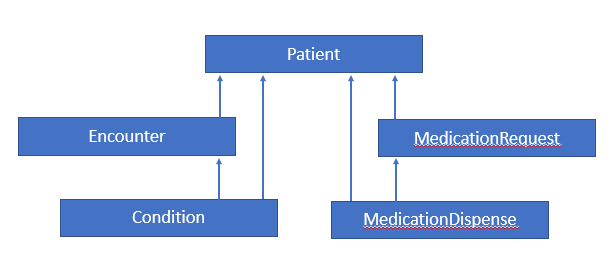
Figure 2‑C - Simple patient information model
[Encounter: "Ambulatory/ED Visit"] E
with [Condition: "Acute Pharyngitis"] P
such that P.onsetDateTime during E.period
and P.abatementDate after end of E.period
This query returns "Ambulatory/ED Visit" encounters performed where the patient also has a condition of "Acute Pharyngitis" that overlaps after the period of the encounter.
The without clause returns only those elements from the primary source that do not have a specific relationship to another source. For example:
[Encounter: "Ambulatory/ED Visit"] E
without [Condition: "Acute Pharyngitis"] P
such that P.onsetDateTime during E.period
and P.abatementDate after end of E.period
This query is the same as the previous example, except that only encounters that do not have overlapping conditions of "Acute Pharyngitis" are returned. In other words, if the such that condition evaluates to true (if the Encounter has an overlapping Condition of Acute Pharyngitis in this case), then that Encounter is not included in the result.
A syntax diagram of a with clause and without clause.
A given query may include any number of with and without clauses in any order, but they must all come before any where, return, or sort clauses.
The such that conditions in the examples above used Timing Relationships (e.g. during, after end of), but any expression may be used, so long as the overall result is boolean-valued. For example:
[MedicationDispense: "Warfarin"] D
with [MedicationPrescription: "Warfarin"] P
such that P.status = 'active'
and P.identifier = D.authorizingPrescription.identifier
This example retrieves all dispense records for active prescriptions of Warfarin.
When multiple with or without clauses appear in a single query, the result will only include elements that meet the such that conditions for all the relationship clauses. For example:
MeasurementPeriodEncounters E
with Pharyngitis P
such that Interval[P.onsetDateTime, P.abatementDateTime] includes E.period
or P.onsetDateTime.value in E.period
with Antibiotics A such that A.dateWritten 3 days or less after start of E.period
This example retrieves all the elements returned by the expression MeasurementPeriodEncounters that have both a related Pharyngitis and Antibiotics result.
The clauses described in the previous section must appear in the correct order in order to specify a valid CQL query. The general order of clauses is:
<primary-source> <alias>
<with-or-without-clauses>
<where-clause>
<return-clause>
<sort-clause>
A query must contain an aliased primary source, but this is the only required clause.
A query may contain zero or more with or without clauses, but they must all appear before any where, return, or sort clauses.
A query may contain at most one where clause, and it must appear after any with or without clauses, and before any return or sort clauses.
A query may contain at most one return clause, and it must appear after any with or without or where clauses, and before any sort clause.
A query may contain at most one sort clause, and it must be the last clause in the query.
For example:
[Encounter: "Inpatient"] E
with [Condition: "Acute Pharyngitis"] P
such that P.onsetDateTime during E.period
and P.abatementDate after end of E.period
where duration in days of E.period >= 120
return Tuple { id: E.id, lengthOfStay: duration in days of E.period }
sort by lengthOfStay desc
This query returns all "Inpatient" encounter events that have an overlapping condition of "Acute Pharyngitis" and a duration of at least 120 days. For each such event, the result will include the id of the event and the duration in days, and the results will be ordered by that duration descending.
As another example, consider a query with multiple without clauses:
SingleLiveBirthEncounter E
without [Condition: "Galactosemia"] G
such that G.onsetDatetime during E.period
without [Procedure: "Parenteral Nutrition"] P
such that P.performed starts during E.period
where not exists ( E.diagnosis ED
where ED.code in "Galactosemia"
)
Even though this example has multiple without clauses, there is still only a single where clause for the query.
Note that the query construct in CQL supports other clauses that are not discussed here. For more information on these, refer to Introducing Scoped Definitions In Queries and Multi-Source Queries.
CQL supports several categories of values:
The result of evaluating any expression in CQL is a value of some type. For example, the expression 5 results in the value 5 of type Integer. CQL is a strongly-typed language, meaning that every value is of some type, and that every operation expects arguments of a particular type.
As a result, any given expression of CQL can be verified as meaningful or be determined meaningless, at least in terms of the operations performed. For example, consider the following expression:
6 + 6
The expression involves the addition of values of type Integer, and so is a meaningful expression of CQL. By contrast:
6 + 'active'
This expression involves the addition of a value of type Integer, 6, to a value of type String, 'active'. This expression is meaningless since CQL does not define addition for values of type Integer and String.
However, there are cases where an expression is meaningful, even if the types do not match exactly. For example, consider the following addition:
6 + 6.0
This expression involves the addition of a value of type Integer, and a value of type Decimal. This is meaningful, but in order to infer the correct result type, the Integer value will be implicitly converted to a value of type Decimal, and the Decimal addition operator will be used, resulting in a value of type Decimal.
To ensure there can never be a loss of information, this implicit conversion will only happen from Integer to Decimal, never from Decimal to Integer.
In the sections that follow, the various categories of values that can be represented in CQL will be considered in more detail.
CQL supports several types of simple values:
| Value | Examples |
|---|---|
| Boolean | true, false, null |
| Integer | 16, -28 |
| Decimal | 100.015 |
| String | 'pending', 'active', 'complete' |
| Date | @2014-01-25 |
| DateTime | @2014-01-25T14:30:14.559 @2014-01T |
| Time | @T12:00 @T14:30:14.559 |
Table 2‑E - Types of simple values that CQL supports
The Boolean type in CQL supports the logical values true, false, and null (meaning unknown). These values are most often encountered as the result of Comparison Operators, and can be combined with other boolean-valued expressions using Logical Operators. Note that CQL supports three-valued logic, see the section on Missing Information in the Author's Guide, as well as the section on Nullological Operators in the Developer's guide for more information.
The Integer type in CQL supports the representation of whole numbers, positive and negative. CQL supports a full set of Arithmetic Operators for performing computations involving whole numbers.
In addition, any operation involving Decimal values can be used with values of type Integer because Integer values can always be implicitly converted to Decimal values.
The Decimal type in CQL supports the representation of real numbers, positive and negative. As with Integer values, CQL supports a full set of Arithmetic Operators for performing computations involving real numbers.
String values within CQL are represented using single-quotes:
'active'
Note that if the value you are attempting to represent contains a single-quote, use a backslash to include it within the string in CQL:
'patient\'s condition is normal'
Comparison of String values in CQL is case-sensitive, meaning that the strings 'patient' and 'Patient' are not equal:
'Patient' = 'Patient'
'Patient' != 'patient'
'Patient' ~ 'patient'
For case- and locale-insensitive comparison, locale-insensitive meaning that an operator will behave identically for all users, regardless of their system locale settings, use the equivalent (~) operator. Note that string equivalence will also "normalize whitespace", meaning that all whitespace characters are treated as equivalent.
CQL supports the representation of Date, DateTime, and Time values.
A syntax diagram of a Date, DateTime and Time format can be seen here.
DateTime values are used to represent an instant along the timeline, known to at least the year precision, and potentially to the millisecond precision. DateTime values are specified using an at-symbol (@) followed by an ISO-8601 textual representation of the DateTime value:
@2014-01-25T14:30
@2014-01-25T14:30:14.559
Date values are used to represent only dates on a calendar, irrespective of the time of day. Date values are specified using an at-symbol (@) followed by an ISO-8601 textual representation of the Date value:
@2014-01-25
Note that the Date value literal format is identical to the date value portion of the DateTime literal format.
Time values are used to represent a time of day, independent of the date. Time value must be known to at least the hour precision, and potentially to the millisecond precision. Time values are specified using an at-symbol with a capital T (@T) followed by an ISO-8601 textual representation of the Time value:
@T12:00
@T14:30:14.559
Note that the Time value literal format is identical to the time value portion of the DateTime literal format.
Only DateTime values may specify a timezone offset, either as UTC (Z), or as a timezone offset. If no timezone offset is specified, the timezone offset of the evaluation request timestamp is used.
For both DateTime and Time values, although the milliseconds are specified with a separate component, seconds and milliseconds are combined and represented as a Decimal for the purposes of comparison, duration, and difference calculation. In other words, when performing comparisons or calculations for precisions of seconds and above, if milliseconds are not specified, the calculation should be performed as though milliseconds had been specified as 0.
For more information on the use of date and time values within CQL, refer to the Date and Time Operators section.
Specifically, because Date, DateTime, and Time values may be specified to varying levels of precisions, operations such as comparison and duration calculation may result in null, rather than the true or false that would result from the same operation involving fully specified values. For a discussion of the effect of imprecision on date and time operations, refer to the Comparing Dates and Times section.
In addition to simple values, CQL supports some types of values that are specific to the clinical quality domain. For example, CQL supports codes, concepts, quantities, ratios, and valuesets.
A quantity is a number with an associated unit. For example:
6 'gm/cm3'
80 'mm[Hg]'
3 months
The number portion of a quantity can be an Integer or Decimal, and the unit portion is a (single-quoted) String representing a valid Unified Code for Units of Measure (UCUM) unit or calendar duration keyword, singular or plural. To avoid the possibility of ambiguity, UCUM codes shall be specified using the case-sensitive (c/s) form.
For time-valued quantities, in addition to the definite duration UCUM units, CQL defines calendar duration keywords for calendar duration units:
| Calendar Duration | Unit Representation | Relationship to Definite Duration UCUM Unit |
|---|---|---|
year/years |
'year' |
~ 1 'a' |
month/months |
'month' |
~ 1 'mo' |
week/weeks |
'week' |
= 1 'wk' |
day/days |
'day' |
= 1 'd' |
hour/hours |
'hour' |
= 1 'h' |
minute/minutes |
'minute' |
= 1 'min' |
second/seconds |
'second' |
= 1 's' |
millisecond/milliseconds |
'millisecond' |
= 1 'ms' |
Durations above days (and weeks) are calendar durations that are not comparable with definite quantity UCUM duration units.
For example, the following quantities are calendar duration quantities:
1 year
4 days
Whereas the following quantities are definite duration quantities:
1 'a'
4 'd'
The table above defines the equality/equivalence relationship between calendar and definite duration quantities. For example, 1 year is not equal (=) to 1 'a' (defined in UCUM as 365.25 'd'), but it is equivalent (~) to 1 'a'.
For all but years and months, calendar durations are both equal and equivalent to the corresponding UCUM definite-time duration unit. Note that due to the possibility of leap seconds, this is not totally accurate, however, for practical reasons, implementations typically ignore leap seconds when performing date/time arithmetic.
For a discussion of the operations available for quantities, see the Quantity Operators section.
A ratio is a relationship between two quantities, expressed in CQL using standard mathematical notation:
1:128
5 'mg' : 10 'mL'
For a discussion of the operations available for ratios, see the Ratio Operators section.
The use of codes to specify meaning within clinical data is ubiquitous. CQL therefore supports a top-level construct for dealing with codes using a structure called Code that is consistent with the way terminologies are typically represented.
The Code type has the following elements:
| Name | Type | Description |
|---|---|---|
| code | String | The actual code within the code system. |
| display | String | A description of the code. |
| system | String | The identifier of the code system. |
| version | String | The version of the code system. |
Table 2‑F - Elements that make up a code type
A syntax diagram of a Code declaration can be seen here.
The following examples illustrate the code declaration:
codesystem "LOINC": 'http://loinc.org'
code "Blood pressure": '55284-4' from "LOINC" display 'Blood pressure'
code "Systolic blood pressure": '8480-6' from "LOINC" display 'Systolic blood pressure'
code "Diastolic blood pressure": '8462-4' from "LOINC" display 'Diastolic blood pressure'
The above declarations can be referenced directly or within a retrieve expression.
A syntax diagram of a Code referencing an existing code can be seen here.
In addition, CQL provides a Code literal that can be used to reference an existing code from a specific code system.
For example
Code '66071002' from "SNOMED-CT" display 'Type B viral hepatitis'
The example specifies the code '66071002' from a previously defined "SNOMED-CT:2014" codesystem, which specifies both the system and version of the resulting code. Note that the display clause is optional. Note that code literals are allowed in CQL for completeness. In general, authors should use code declarations rather than code literals when using codes directly.
This use of code declarations to reference a single code in a CQL expression is referred to as a direct reference code:
code "Discharge to home for hospice care (procedure)": '428361000124107' from "SNOMEDCT"
define "Encounters Discharged to Hospice":
"Encounters" E where E.dischargeDisposition ~ "Discharge to home for hospice care (procedure)"
Note the use of the equivalent operator (~) rather than equality (=). For codes, equivalence tests only that the code system and code are the same, but does not check the code system version.
Although CQL supports both version-specific and version-independent specification of and comparison to direct reference codes, artifact authors should use version-independent direct reference codes and comparisons unless there is a specific reason not to (such as the code is retired in the current version). Even when using version-specific direct reference codes, authors should use equivalence for the comparison (again, unless there is a specific reason to use version-specific comparison with equality).
When using direct reference codes, authors should use the name of the code as defined externally to avoid introducing any potential confusion of meaning.
Using direct-reference codes can be more difficult for implementations to map to local settings, because modification of the codes for local usage may require modification of the CQL, as opposed to the use of a value set which many systems already have support for mapping to local codes.
Within clinical information, multiple terminologies can often be used to code for the same concept. As such, CQL defines a top-level construct called Concept that allows for multiple codes to be specified.
The Concept type has the following elements:
| Name | Type | Description |
|---|---|---|
| codes | List<Code> | The list of semantically equivalent codes representing the concept. |
| display | String | A description of the concept. |
Table 2‑G - Elements that make up a Concept type
Note that the semantics of Concept are such that the codes within a given concept should be semantically about the same concept (e.g. the same concept represented in different code systems, or the same concept from the same code system represented at different levels of detail), but CQL itself will make no attempt to ensure that is the case. Concepts should never be used as a surrogate for proper valueset definition.
The following example illustrates the concept declaration:
codesystem "SNOMED-CT": 'urn:oid:2.16.840.1.113883.6.96'
codesystem "ICD-10-CM": 'urn:oid:2.16.840.1.113883.6.90'
code "Hepatitis Type B (SNOMED)": '66071002' from "SNOMED-CT" display 'Viral hepatitis type B (disorder)'
code "Hepatitis Type B (ICD-10)": 'B18.1' from "ICD-10-CM" display 'Chronic viral hepatitis B without delta-agent'
concept "Type B Hepatitis": { "Hepatitis Type B (SNOMED)", "Hepatitis Type B (ICD-10)" } display 'Type B Hepatitis'
The above declaration can be referenced directly or within a retrieve expression.
A syntax diagram of a Concept declaration can be seen here.
As with codes, local names for concept declarations should be consistent with external declarations to avoid introducing any confusion of meaning.
The following example illustrates the use of a Concept literal:
Concept {
Code '66071002' from "SNOMED-CT",
Code 'B18.1' from "ICD-10-CM"
} display 'Type B viral hepatitis'
This example constructs a Concept with display 'Type B viral hepatitis' and code of '66071002'.
A syntax diagram of a Concept literal can be seen here.
As a value, a valueset is simply a list of Code values. However, CQL allows valuesets to be used without reference to the codes involved by declaring valuesets as a special type of value within the language.
A syntax diagram of a valueset declaration can be seen here.
The following example illustrates some typical valueset declarations:
valueset "Acute Pharyngitis": 'urn:oid:2.16.840.1.113883.3.464.1003.102.12.1011'
valueset "Acute Tonsillitis": 'urn:oid:2.16.840.1.113883.3.464.1003.102.12.1012'
valueset "Ambulatory/ED Visit": 'urn:oid:2.16.840.1.113883.3.464.1003.101.12.1061'
Each valueset declaration defines a local identifier that can be used to reference the valueset within the library, as well as the global identifier for the valueset, typically an object identifier (OID) or uniform resource identifier (URI).
These valueset identifiers can then be used throughout the library. For example:
define "Pharyngitis": [Condition: "Acute Pharyngitis"]
This example defines Pharyngitis as any Condition where the code is in the "Acute Pharyngitis" valueset.
Whenever a valueset reference is actually evaluated, the resulting expansion set, or list of codes, depends on the binding specified by the valueset declaration. By default, all valueset bindings are dynamic, meaning that the expansion set should be constructed using the most current published version of the valueset.
However, CQL also allows for static bindings which allow two components to be set:
If the binding specifies a valueset version, then the expansion set must be derived from that specific version. This does not restrict the code system versions available for use, therefore more than one expansion set is possible.
If any code systems are specified, they indicate which version of the particular code system should be used when constructing the expansion set. As with valuesets, if no code system version is specified, the expansion set should be constructed using the most current published version of the codesystem. Note that if the external valueset definition explicitly states that a particular version of a code system should be used, then it is an error if the code system version specified in the CQL static binding does not match the code system version specified in the external valueset definition. To create a reliable static binding where only one value set expansion set is possible, both the value set version and the code system versions should be specified.
The following example illustrates the use of static binding based only on the version of the valueset:
valueset "Diabetes": 'urn:oid:2.16.840.1.113883.3.464.1003.103.12.1001' version '20140501'
The next example illustrates a static binding based on both the version of the valueset, as well as the versions of the code systems within the valueset:
codesystem "SNOMED-CT:2013-09": 'urn:oid:2.16.840.1.113883.6.96' version '2031-09'
codesystem "ICD-9-CM:2014": 'urn:oid:2.16.840.1.113883.6.103' version '2014'
codesystem "ICD-10-CM:2014": 'urn:oid:2.16.840.1.113883.6.90' version '2014'
valueset "Diabetes": 'urn:oid:2.16.840.1.113883.3.464.1003.103.12.1001' version '20140501'
codesystems { "SNOMED-CT:2013-09", "ICD-9-CM:2014", "ICD-10-CM:2014" }
When using value set declarations, authors should use the name of the value set as defined externally to avoid introducing any potential confusion of meaning. One exception to this is when different value sets are defined with the same name in an external repository, in which case some additional aspect is required to ensure uniqueness of the names within the CQL library. See the Terminology Operators section for more information on the use of valuesets within CQL.
In addition to their use as part of valueset definitions, codesystem definitions can be referenced directly within an expression, just like valueset definitions. See the Valuesets section for an example of a codesystem declaration.
For example:
codesystem "LOINC": 'http://loinc.org'
define "LOINC Observations": [Observation: "LOINC"]
The above example retrieves all observations coded using LOINC codes.
See the Terminology Operators section for more information on the use of codesystems within CQL.
Structured values, or tuples, are values that contain named elements, each having a value of some type. Clinical information such as a Medication, a Condition, or an Encounter is represented using tuples.
For example, the following expression retrieves the first Condition with a code in the "Acute Pharyngitis" valueset for a patient:
define "FirstPharyngitis":
First([Condition: "Acute Pharyngitis"] C sort by onsetDateTime desc)
The values of the elements of a tuple can be accessed using a dot qualifier (.) followed by the name of the element:
define "PharyngitisOnSetDateTime": FirstPharyngitis.onsetDateTime
Tuples can also be constructed directly using a tuple selector.
A syntax diagram of a tuple selector can be seen here.
For example:
define "Info": Tuple { Name: 'Patrick', DOB: @2014-01-01 }
If the tuple is of a specific type, the name of the type can be used instead of the Tuple keyword:
define "PatientExpression": Patient { Name: 'Patrick', DOB: @2014-01-01 }
If the name of the type is specified, the tuple selector may only contain elements that are defined on the type, and the expressions for each element must evaluate to a value of the defined type for the element. Any elements defined in the class but not present in the selector will be null.
Note that tuples can contain other tuples, as well as lists:
define "Info":
Tuple {
Name: 'Patrick',
DOB: @2014-01-01,
Address: Tuple { Line1: '41 Spinning Ave', City: 'Dayton', State: 'OH' },
Phones: { Tuple { Number: '202-413-1234', Use: 'Home' } }
}
Accordingly, element access can nest as deeply as necessary:
Info.Address.City
This accesses the City element of the Address element of Info. Lists can be traversed within element accessors using the list indexer ([]):
Info.Phones[0].Number
This accesses the Number element of the first element of the Phones list within Info.
In addition, to simplify path traversal for models that make extensive use of list-valued attributes, the indexer can be omitted:
Info.Phones.Number
The result of this invocation is a list containing the Number elements of all the Phones within Info.
Because clinical information is often incomplete, CQL provides a special construct, null, to represent an unknown or missing value or result. For example, the admission date of an encounter may not be known. In that case, the result of accessing the admissionDate element of the Encounter tuple is null.
In order to provide consistent behavior in the presence of missing information, CQL defines null behavior for all operations. For example, consider the following expression:
define "PharyngitisOnSetDateTime": FirstPharyngitis.onsetDateTime
If the onsetDateTime is not present, the result of this expression is null. Furthermore, nulls will in general propagate, meaning that if the result of FirstPharyngitis is null, the result of accessing the onsetDateTime element is also null.
For more information on missing information, see the Nullological Operators section.
CQL supports the representation of lists of any type of value (including other lists). Although some operations may result in lists containing mixed types, in normal use cases, lists contain items that are all of the same type.
Lists can be constructed directly, as in:
{ 1, 2, 3, 4, 5 }
But more commonly, lists of tuples are the result of retrieve expressions. For example:
[Condition: code in "Acute Pharyngitis"]
This expression results in a list of tuples, where each tuple’s elements are determined by the data model in use.
Lists in CQL use zero-based indexes, meaning that the first element in a list has index 0. For example, given the list of integers:
{ 6, 7, 8, 9, 10 }
The first element is 6 and has index 0, the second element is 7 and has index 1, and so on.
Note that in general, clinical data may be expected to contain various types of collections such as sets, bags, lists, and arrays. For simplicity, CQL deals with all collections using the same collection type, the list, and provides operations to enable dealing with different collection types. For example, a set is a list where each element is unique, and any given list can be converted to a set using the distinct operator.
For a description of the distinct operator, as well as other operations that can be performed with lists, refer to the List Operators section.
CQL supports the representation of intervals, or ranges, of values of various types. In particular, intervals of date and time values, and ranges of integers and reals.
Intervals in CQL are represented by specifying the low and high points of the Interval and whether the boundary is inclusive (meaning the boundary point is part of the interval) or exclusive (meaning the boundary point is excluded from the interval). Following standard mathematics notation, inclusive (closed) boundaries are indicated with square brackets, and exclusive (open) boundaries are indicated with parentheses.
A syntax diagram of an Interval construct can be seen here.
For example:
Interval[3, 5)
This expression results in an Interval that contains the integers 3 and 4, but not 5.
Interval[3.0, 5.0)
This expression results in an Interval that contains all the real numbers >= 3.0 and < 5.0.
Intervals can be constructed based on any type that supports unique and ordered comparison. For example:
Interval[@2014-01-01T00:00:00.0, @2015-01-01T00:00:00.0)
This expression results in an Interval that begins at midnight on January 1, 2014, ends just before midnight on December 31, 2014 and is equivalent to the following interval:
Interval[@2014-01-01T00:00:00.0, @2014-12-31T23:59:59.999]
Furthermore, take the following example:
Interval[@2014-01-01, @2015-01-01)
This expression results in an Interval that begins on January 1, 2014 at an undefined time, ends at an undefined time on December 31, 2014 and is equivalent to the following interval:
Interval[@2014-01-01, @2014-12-31]
Note that the ending boundary must be greater than or equal to the starting boundary to construct a valid interval. Attempting to specify an invalid Interval will result in a run-time error. For example:
Interval[1, -1] // Invalid interval, this will result in an error
It is valid to construct an Interval with the same start and end boundary, so long as the boundaries are inclusive:
Interval[1, 1] // Unit interval containing only the point 1
Interval[1, 1) // Invalid interval, conflicting to say it both includes and excludes 1
Such an Interval contains only a single point and can be called a unit interval. For unit intervals, the point from operator can be used to extract the single point from the interval. Attempting to use point from on a non-unit-interval will result in a run-time error.
point from Interval[1, 1] // Results in 1
point from Interval[1, 5] // Invalid extractor, this will result in an error
In addition to retrieving clinical information about a patient or set of patients, the expression of clinical knowledge artifacts often involves the use of various operations such as comparison, logical operations such as and and or, computation, and so on. To ensure that the language can effectively express a broad range of knowledge artifacts, CQL includes a comprehensive set of operations. In general, these operations are all expressions in that they can be evaluated to return a value of some type, and the type of that return value can be determined by examining the types of values and operations involved in the expression.
This means that for each operation, CQL defines the number and type of each input (argument) to the operation and the type of the result, given the types of each argument.
The following sections define the operations that can be used within CQL, divided into semantically related categories.
For all the comparison operators, the result type of the operation is Boolean, meaning they may result in true, false, or null (meaning unknown). In general, if either or both of the values being compared is null, the result of the comparison is null.
The most basic operation in CQL involves comparison of two values. This is accomplished with the built-in comparison operators:
| Operator | Name | Description |
|---|---|---|
| = | Equality | Returns true if the arguments are the same value. Returns false if arguments are not the same value. Returns null if either or both arguments are null |
| != | Inequality | Returns true if the arguments are not the same value. Returns false if the arguments are the same value. Returns null if either or both arguments are null |
| > | Greater than | Returns true if the left argument is greater than the right argument. Returns false if the left argument is less than the right argument, or if the arguments are the same value. Returns null if either or both arguments are null |
| < | Less than | Returns true if the left argument is less than the right argument. Returns false if the left argument is greater than the right argument, or if the arguments are the same value. Returns null if either or both arguments are null |
| >= | Greater than or equal | Returns true if the left argument is greater than or equal to the right argument. Returns false if the left argument is less than the right argument. Returns null if either or both arguments are null |
| <= | Less than or equal | Returns true if the left argument is less than or equal to the right argument. Returns false if the left argument is greater than the right argument. Returns null if either or both arguments are null |
| between | Returns true if the first argument is greater than or equal to the second argument, and less than or equal to the third argument. Returns false if the first argument is less than the second argument or greater than the third argument. Returns null if any or all arguments are null. | |
| ~ | Equivalent | Returns true if the arguments are equivalent in value, or are both null; otherwise false |
| !~ | Inequivalent | Returns true if the arguments are not equivalent and false otherwise. |
Table 2‑H - The built-in comparison operators that CQL provides
In general, the equality and inequality operators can be used on any type of value within CQL, but both arguments must be the same type. For example, the following equality comparison is legal, and returns true:
5 = 5
However, the following equality comparison is invalid because numbers and strings cannot be meaningfully compared:
5 = 'completed'
Attempting to compare numbers and strings as in this example will result in an error message indicating that there is no equality (=) operator available to compare numbers and strings.
For Decimal values, equality is defined to ignore trailing zeroes.
For Date and Time values, equality is defined to account for the possibility that the Date and Time values involved are specified to varying levels of precision. For a complete discussion of this behavior, refer to Comparing Dates and Times.
For structured values, equality returns true if the values being compared are the same type (meaning they have the same types of elements) and the values for all elements that have values are the same value. For example, the following comparison returns true:
Tuple { id: 'ABC-001', name: 'John Smith' } = Tuple { id: 'ABC-001', name: 'John Smith' }
As another example, if one tuple has a value for an element that is not present in the other tuple, the result is null:
Tuple { x: 1, y: 1 } = Tuple { x: 1, y: null }
As well, tuple equality is defined as a conjunction of equality comparisons of the elements, allowing for known unequal values to be determined. For example, the following comparison returns false because the y elements are known unequal:
Tuple { x: 1, y: 1 } = Tuple { x: null, y: 2 }
For lists, equality returns true if the lists contain the same elements in the same order. For example, the following lists are equal:
{ 1, 2, 3, 4, 5 } = { 1, 2, 3, 4, 5 }
And the following lists are not equal:
{ 1, 2, 3, 4, 5 } != { 5, 4, 3, 2, 1 }
Note that in the above example, if the second list was sorted ascending prior to the comparison, the result would be true.
For intervals, equality returns true if the intervals use the same point type and cover the same range. For example:
Interval[1,5] = Interval[1,6)
This returns true because the intervals cover the same set of points, 1 through 5.
The relative comparison operators (>, >=, <, <=) can be used on types of values that have a natural ordering such as numbers, strings, and dates.
The between operator is shorthand for comparison of an expression against an upper and lower bound. For example:
4 between 2 and 8
This expression is equivalent to:
4 >= 2 and 4 <= 8
For all the comparison operators, the result type of the operation is Boolean. Note that because CQL uses three-valued logic, if either or both of the arguments is null, the result of the comparison is null (meaning unknown). This is true for all the comparison operators except equivalent (~) and not equivalent (!~). The equivalent operator is generally the same as equality, except that it returns true if both of the arguments are null, and false if one argument is null and the other is not:
define "NullEqualityTest": 1 = null
define "NullEquivalenceTest": 1 ~ null
The expression NullEqualityTest results in null, whereas the expression NullEquivalenceTest results in false.
In addition, equivalence is defined more loosely than equality for some types:
For more detail, see the definitions of Equal and Equivalent in the CQL reference.
Combining the results of comparisons and other boolean-valued expressions is essential and is performed in CQL using the following logical operations:
| Operator | Description |
|---|---|
| and | Logical conjunction |
| or | Logical disjunction |
| xor | Exclusive logical disjunction |
| not | Logical negation |
Table 2‑I - Logical operations that CQL provides
The following examples illustrate some common uses of logical operators:
AgeInYears() >= 18 and AgeInYears() < 24
INRResult > 5 or DischargedOnOverlapTherapy
Note that all these operators are defined using three-valued logic, which is defined specifically to ensure that certain well-established relationships that hold in standard Boolean (two-valued) logic also hold. The complete semantics for each operator are described in the Logical Operators section of Appendix B – CQL Reference.
To ensure that CQL expressions can be freely rewritten by underlying implementations, there is no expectation that an implementation respect short-circuit evaluation, short circuit evaluation meaning that an expression stops being evaluated once the outcome is determined. With regard to performance, implementations may use short-circuit evaluation to reduce computation, but authors should not rely on such behavior, and implementations must not change semantics with short-circuit evaluation. If a condition is needed to ensure correct evaluation of a subsequent expression, the if or case expressions should be used to guarantee that the condition determines whether evaluation of an expression will occur at run-time.
The expression of clinical logic often involves numeric computation, and CQL provides a complete set of arithmetic operations for expressing computational logic. In general, these operators have the standard semantics for arithmetic operators, with the general caveat that unless otherwise stated in the documentation for a specific operation, if any argument to an operation is null, the result is null. In addition, calculations that cause arithmetic overflow or underflow, or otherwise cannot be performed (such as division by 0) will result in null, rather than a run-time error.
The following table lists the arithmetic operations available in CQL:
| Operator | Name | Description |
|---|---|---|
| + | addition | Performs numeric addition of its arguments |
| - | subtraction | Performs numeric subtraction of its arguments |
| * | multiply | Performs numeric multiplication of its arguments |
| / | divide | Performs numeric division of its arguments |
| div | truncated divide | Performs integer division of its arguments |
| mod | modulo | Computes the remainder of the integer division of its arguments |
| Ceiling | Returns the first integer greater than or equal to its argument | |
| Floor | Returns the first integer less than or equal to its argument | |
| Truncate | Returns the integer component of its argument | |
| Abs | Returns the absolute value of its argument | |
| - | negate | Returns the negative value of its argument |
| Round | Returns the nearest numeric value to its argument, optionally specified to a number of decimal places for rounding | |
| Ln | natural logarithm | Computes the natural logarithm of its argument |
| Log | logarithm | Computes the logarithm of its first argument, using the second argument as the base |
| Exp | exponent | Raises e to the power given by its argument |
| ^ | exponentiation | Raises the first argument to the power given by the second argument |
Table 2‑J - Arithmetic operations that CQL provides
Operations on date and time data are an essential component of expressing clinical knowledge, and CQL provides a complete set of date and time operators. These operators broadly fall into five categories:
In addition to the literals described in the Date, DateTime, and Time section, the Date, DateTime, and Time operators allow for the construction of specific Date and Time values based on the values for their components. For example:
Date(2014, 7, 5)
DateTime(2014, 7, 5, 4, 0, 0, 0, -7)
The first example constructs the Date July 5, 2014. The second example constructs a DateTime of July 5, 2014, 04:00:00.0 UTC-07:00 (Mountain Standard Time).
The DateTime operator takes the following arguments:
| Name | Type | Description |
|---|---|---|
| Year | Integer | The year component of the DateTime |
| Month | Integer | The month component of the DateTime |
| Day | Integer | The day component of the DateTime |
| Hour | Integer | The hour component of the DateTime |
| Minute | Integer | The minute component of the DateTime |
| Second | Integer | The second component of the DateTime |
| Millisecond | Integer | The millisecond component of the DateTime |
| Timezone Offset | Decimal | The timezone offset component of the DateTime (in hours) |
Table 2‑K - The arguments that the DateTime operator takes
The Date operator takes only the first three arguments: Year, Month, and Day.
At least one component other than timezone offset must be provided, and for any particular component that is provided, all the components of broader precision must be provided. For example:
Date(2014)
Date(2014, 7)
Date(2014, 7, 11)
Date(null, null, 11) // invalid
The first three expressions above are valid, constructing dates with a specified precision of years, months, and days, respectively. However, the fourth expression is invalid, because it attempts to create a date with a day but no year or month component.
The only component that is ever defaulted is the timezone offset component. If no timezone offset component is supplied, the timezone offset component is defaulted to the timezone offset of the timestamp associated with the evaluation request.
The Time operator takes the following arguments:
| Name | Type | Description |
|---|---|---|
| Hour | Integer | The hour component of the DateTime |
| Minute | Integer | The minute component of the DateTime |
| Second | Integer | The second component of the DateTime |
| Millisecond | Integer | The millisecond component of the DateTime |
Table 2‑L - The arguments that the Time operator takes
As with the Date and DateTime operators, at least the first component must be supplied, and for any particular component that is provided, all components of broader precision must be provided. For DateTime, if timezone offset is not supplied, it will be defaulted to the timezone offset of the timestamp associated with the evaluation request.
In addition to the ability to construct specific dates and times using components, CQL supports three operators for retrieving the current date and time:
| Operator | Description |
|---|---|
| Now | Returns the date and time of the start timestamp associated with the evaluation request |
| Today | Returns the date (with no time components) of the start timestamp associated with the evaluation request |
| TimeOfDay | Returns the time-of-day of the start timestamp associated with the evaluation request |
Table 2‑M - The operators that CQL supports for retrieving the current date and time
The current date and time operators are defined based on the timestamp of the evaluation request for two reasons:
By defining the DateTime construction operators in this way, most clinical logic can ignore timezone offset information, and the logic will be evaluated with the expected semantics. However, if timezone offset information is relevant to a particular calculation, it can still be accessed as a component of each DateTime value.
In addition, all operations on DateTime values are defined to take timezone offset information into account, ensuring that DateTime operations perform correctly and consistently.
As discussed in the Quantities section above, CQL supports the construction of time durations using the name of the precision as the unit for a quantity. For example:
3 months
1 year
5 minutes
Valid time duration units are:
year
years
month
months
week
weeks
day
days
hour
hours
minute
minutes
second
seconds
millisecond
milliseconds
Note that CQL supports both plural and singular duration units to allow for the most natural expression, but that no attempt is made to enforce singular or plural usage.
As noted in the Quantities section, UCUM time-period units can be used to express definite-duration quantities. However, definite-duration time-period units above days (and weeks) cannot appear in date and time arithmetic calculations. See the Date and Time Arithmetic section for more detailed discussion.
For a detailed discussion of calendar calculation semantics, refer to Appendix H – Time Interval Calculation Examples.
For comparisons involving time durations (where no anchor to a calendar is available), the duration of a year is considered to be 365 days, and the duration of a month is considered to be 30 days. Duration calculations involving weeks consider a week as equivalent to 7 days.
CQL supports comparison of Date and Time values using the expected comparison operators. Note however, that when Date and Time values are not specified completely, the result may be null, depending on whether there is enough information to make an accurate determination. In general, CQL treats Date and Time values that are only known to some specific precision as an uncertainty over the range at the first unspecified precision. For example:
Date(2014)
This value can be read as “some date within the year 2014”, because only the year component is known. Applying these semantics yields the intuitively correct result when comparing Date and Time values with varying levels of precision.
Date(2012) < Date(2014, 2, 15)
This example returns true because even though the month and day of the first date are unknown, the year, 2012, is known to be less than the year of the second date, 2014. By contrast:
Date(2015) < Date(2014, 2, 15)
The result in this example is false because the year, 2015, is not less than the year of the second date. And finally:
Date(2014) < Date(2014, 2, 15)
The result in this example is null because the first date could be any date within the year 2014, so it could be less than the second date, but it could be greater.
Note that due to variability in the way week numbers are calculated, weeks are not valid for Date or DateTime comparisons and will result in an error.
When comparing DateTime values with different timezone offsets, implementations should normalize to the timezone offset of the evaluation request timestamp, but only when the comparison precision is hours, minutes, seconds, or milliseconds.
Date and time comparisons are performed by comparing the values at each precision, beginning with years, and proceeding to the finest precision specified in either input, with seconds and milliseconds treated as a single precision using a Decimal. This means that if one date or time is specified to a different level of precision than the other, the result of the comparison may be null, or unknown. However, it is often the case that comparisons should only be carried to a specific level of precision. To enable this, CQL provides precision-based versions of the comparison operators:
| Operator | Precision-based Operator |
|---|---|
| = | same as |
| < | before |
| > | after |
| <= | same or before |
| >= | same or after |
Table 2‑N - The precision-based comparison operators for Date and Time comparisons
If no precision is specified, these operators are synonyms for the symbolic conversion operators, and the comparisons are performed in the same way (from years, or hours for Time values, down to the finest precision specified in either input, with seconds and milliseconds treated as a single precision using a decimal). If a precision is specified, the comparison is performed beginning with years and proceeding to the specified level of precision. For example:
Date(2014) same year as Date(2014, 7, 11)
Date(2014, 7) same month as Date(2014, 7, 11)
DateTime(2014, 7, 11) same day as DateTime(2014, 7, 11, 14, 0, 0)
Each of these expressions returns true because the Date and Time values are equal at the specified level of precision and above. For example, same month as means the same year and the same month.
Note that when explicitly comparing or calculating at the millisecond precision, the values are considered separated (i.e. one value having milliseconds and the other not would result in a null or uncertainty).
Note: To compare a specific component of two dates, use the extraction operators covered in the next section.
For relative comparisons involving equality, the same as operator is suffixed with before or after:
Date(2015) same year or after Date(2014, 7, 11)
Date(2014, 4) same month or before Date(2014, 7, 11)
DateTime(2014, 7, 15) same day or after DateTime(2014, 7, 11, 14, 0, 0)
Each of these expressions also returns true. And finally, for the relative inequalities (< and >):
Date(2015) after year of Date(2014, 7, 11)
Date(2014, 4) before month of Date(2014, 7, 11)
DateTime(2014, 7, 15) after day of DateTime(2014, 7, 11, 14, 0, 0)
Each of these expressions also returns true.
Note that these operators may still return null if the Date and Time values involved have unspecified components at or above the specified comparison precision. For example:
Date(2014, 7, 15) after hour of DateTime(2014, 7, 11, 14, 0, 0)
The result in this example is null because the first date has no hour component.
Given a Date and Time value, CQL supports extraction of any of the components. For example:
date from X
year from X
minute from X
These examples extract the date from X, the year from X, and the minute from X. The following table lists the valid extraction components and their resulting types:
| Component | Description | Result Type |
|---|---|---|
| date from X | Extracts the date of its argument (with no time components) | Date |
| time from X | Extracts the time of its argument | Time |
| year from X | Extracts the year component its argument | Integer |
| month from X | Extracts the month component of its argument | Integer |
| day from X | Extracts the day component of its argument | Integer |
| hour from X | Extracts the hour component of its argument | Integer |
| minute from X | Extracts the minute component of its argument | Integer |
| second from X | Extracts the second component of its argument | Integer |
| millisecond from X | Extracts the millisecond component of its argument | Integer |
| timezoneoffset from X | Extracts the timezone offset component of its argument | Decimal |
Table 2‑O - The valid extraction components for extracting Date and Time components
Note specifically that week from X is not valid; due to variability in the way week numbers are determined, the calculation of week number is not prescribed.
Note that if X is null, the result is null. If a date and time value does not have a particular component specified, extracting that component will result in null. Note also that if the timezone offset component for a particular date and time value was not provided as part of the constructor, because the value is defaulted to the timezone offset of the evaluation request, the result of extracting the timezone offset component will be the timezone offset of the evaluation request, not null.
When extracting the Time from a DateTime value, implementations should normalize to the timezone offset of the evaluation request timestamp.
By using quantities of time durations, CQL supports the ability to perform calendar arithmetic with the expected semantics for durations with variable numbers of days such as months and years. The arithmetic addition and subtraction symbols (+ and -) are used for this purpose. For example:
Today() - 1 year
The above expression computes the date one year before today, taking into account variable length years and months. Any valid time duration can be added to or subtracted from any Date and Time value.
Note that as with the numeric arithmetic operators, if either or both arguments are null, the result of the operation is null.
For partial date/time values where the time-valued quantity is more precise than the partial date/time, the operation is performed by converting the time-based quantity to the most precise value specified in the first argument (truncating any resulting decimal portion) and then adding it to (or subtracting it from) the first argument. For example, consider the following addition:
DateTime(2014) + 24 months
This example results in the value DateTime(2016) even though the DateTime value is not specified to the level of precision of the time-valued quantity.
Note also that this means that if decimals appear in the time-valued quantities, the fractional component will be ignored. For example:
@2016-01-01 – 1.1 years
Will result in the value @2015-01-01, the decimal component is truncated. When this decimal truncation occurs, run-time implementations should issue a warning. When it’s possible to determine at compile-time that this truncation will occur, a warning should be issued by the translator.
To avoid the potential confusion of calendar-based date/time arithmetic with definite duration date/time arithmetic, CQL defines definite-duration date/time arithmetic for seconds and below, and calendar-based date/time arithmetic for seconds and above. At the second, calendar-based and definite-duration-based date/time arithmetic are identical. Using a definite-quantity duration above days (and weeks) in a date/time arithmetic calculation will result in a run-time error.
Within CQL, calculations involving date/times and calendar durations shall use calendar semantics as specified in ISO8601. Specifically:
| Date/Time Precision | Calendar Semantic Description |
|---|---|
| year | The year, positive or negative, is added to the year component of the date or time value. If the resulting year is out of range, an error is thrown. If the month and day of the date or time value is not a valid date in the resulting year, the last day of the calendar month is used. |
| month | The month, positive or negative is divided by 12, and the integer portion of the result is added to the year component. The remaining portion of months is added to the month component. If the resulting date is not a valid date in the resulting year, the last day of the resulting calendar month is used. |
| week | The week, positive or negative, is multiplied by 7, and the resulting value is added to the day component, respecting calendar month and calendar year lengths. |
| day | The day, positive or negative, is added to the day component, respecting calendar month and calendar year lengths. |
| hour | The hours, positive or negative, are added to the hour component, with each 24 hour block counting as a calendar day, and respecting calendar month and calendar year lengths. |
| minute | The minutes, positive or negative, are added to the minute component, with each 60 minute block counting as an hour, and respecting calendar month and calendar year lengths. |
| second | The seconds, positive or negative, are added to the second component, with each 60 second block counting as a minute, and respecting calendar month and calendar year lengths. |
| millisecond | The milliseconds, positive or negative, are added to the millisecond component, with each 1000 millisecond block counting as a second, and respecting calendar month and calendar year lengths. |
Table 2‑P - The ISO8601 calendar semantics that should be used for calculations involving Date and Time
Although the CQL specification does not support arithmetic with definite quantity durations above days (and weeks), data models that use UCUM for all quantities may support implicit conversion from UCUM definite durations to calendar durations. See Use of FHIR Quantity for an example.
In addition to constructing durations, CQL supports the ability to compute duration and difference between two DateTimes. For duration, the calculation is performed based on the calendar duration for the precision. For difference, the calculation is performed by counting the number of boundaries of the specific precision crossed between the two dates.
months between X and Y
This example calculates the number of months between its arguments. For variable length precisions (months and years), the operation uses the calendar length of the precision to determine the number of periods.
For example, the following expression returns 2:
months between @2014-01-01 and @2014-03-01
This is because there are two whole calendar months between the two dates. Fractional months are not included in the result. This means that the following expression also returns 2:
months between @2014-01-01 and @2014-03-15
For difference, the calculation is concerned with the number of boundaries crossed:
difference in months between X and Y
The above example calculates the number of month boundaries crossed between X and Y.
To illustrate the difference between the two calculations, consider the following examples:
duration in months between @2014-01-31 and @2014-02-01
difference in months between @2014-01-31 and @2014-02-01
The first example returns 0 because there is less than one calendar month between the two dates. The second example, however, returns 1, because a month boundary was crossed between the two dates.
The following duration units are valid for the duration and difference operators:
years
months
weeks
days
hours
minutes
seconds
milliseconds
If the first argument is after the second, the result will be negative.
For calculations involving weeks, Sunday is considered the first of the week for the purposes of determining boundaries, and the duration of a week is always considered to be seven (7) days.
In addition, if either date or time value involved is not specified to the level of precision for the duration or difference being calculated, the result will be an uncertainty covering the range of possible values for the duration. Subsequent comparisons using this uncertainty may result in null rather than true or false. For a detailed discussion of the behavior of uncertainties, refer to the Uncertainty section.
When computing duration or difference between DateTime values with different timezone offsets, implementations should normalize to the timezone offset of the evaluation request timestamp, but only when the comparison precision is hours, minutes, seconds, or milliseconds.
If either or both arguments are null, the result is null.
For a detailed set of examples of calculating time intervals, please refer to Appendix H - Time Interval Calculation Examples.
Clinical information often contains not only date and time information as timestamps (points in time), but intervals of time, such as the effective time for an encounter or condition. Moreover, clinical logic involving this information often requires the ability to relate this temporal information. For example, a clinical quality measure might look for “patients with an inpatient encounter during which a condition started”. CQL provides an exhaustive set of operators for describing these types of temporal relationships between clinical information.
These interval operations can be broadly categorized as follows:
General interval operators in CQL provide basic operations for dealing with interval values, including construction, extraction, and membership.
Interval values can be constructed using the interval selector, as discussed in Interval Values above.
Membership testing for intervals can be done using the in and contains operators. For example:
Interval[3, 5) contains 4
4 in Interval[3, 5)
These two expressions are equivalent (inverse of each other) and both return true.
The starting and ending points for an interval can be determined using the start of and end of operators:
start of Interval[3, 5)
end of Interval[3, 5)
The first expression above returns 3, while the second expression returns 4.
Property expressions can also be used to access the boundary points and closed indicators for interval types using the property names low, high, lowClosed, and highClosed:
Interval[3, 5).high
Interval[3, 5).highClosed
The first expression above returns 5, and the second expression returns false.
To extract a point from an interval, the point from operator is used:
point from Interval[3, 3]
point from Interval[3, 4)
The two expressions are equivalent and both return 3.
Note that the point from operator may only be used on a unit interval, or an interval containing a single point. Attempting to extract a point from an interval with a size greater than one will result in a run-time error.
The starting and ending point of an interval may be null, the meaning of which depends on whether the interval is closed (inclusive) or open (exclusive). If a boundary point is null and the boundary is exclusive, the boundary is considered unknown, and represents an uncertainty between the boundary and the minimum or maximum value for the point type of the interval. In this case, operations involving that point may return null. For example:
Interval[3, null) contains 5
This expression results in null. However, if the point is null and the interval boundary is inclusive, the boundary is interpreted as the beginning or ending of the range of the point type. For example:
Interval[3, null] contains 5
This expression returns true because the null ending boundary is inclusive and is therefore interpreted as extending to the end of the range of possible values for the point type of the interval.
For numeric intervals, CQL defines a width operator, which returns the ending boundary minus the starting boundary:
width of Interval[3, 5)
width of Interval[3, 5]
The first expression returns 1 (ending boundary of 4, minus the starting boundary of 3), while the second expression returns 2 (ending boundary of 5, minus the starting boundary of 3).
For date and time intervals, CQL defines a duration of operator as well as a difference of operator, both of which are defined in the same way as the date and time duration and difference operators, respectively. For example:
duration in days of X
difference in days of X
These expressions are equivalent to:
duration in days between start of X and end of X
difference in days between start of X and end of X
The first expression returns the number of whole days between the starting and ending dates of the interval X, while the second expression returns the number of day boundaries crossed between the starting and ending dates of the interval X.
CQL supports comparison of two interval values using a complete set of operations. The following table describes these operators with a diagram showing the relationship between two intervals that is characterized by each operation:
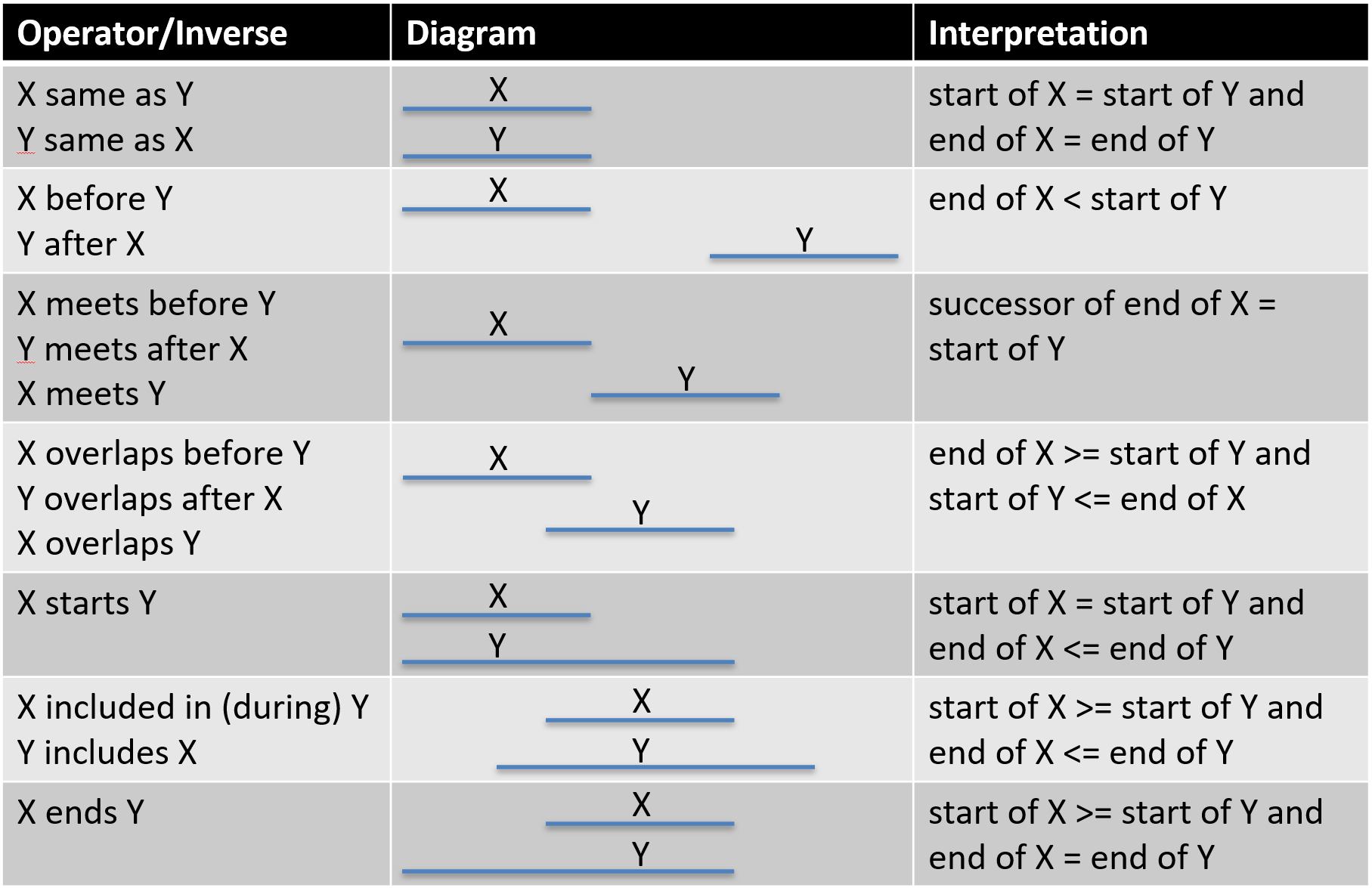
Table 2‑Q - Comparison of two interval values using a complete set of operations
Each of these operators returns true if the intervals X and Y are in the given relationship to each other. If either or both arguments are null, the result is null. Otherwise, the result is false.
In addition, CQL allows the meets operator to be invoked without the before or after suffix, indicating that either relationship should return true. In other words, X meets Y is equivalent to X meets before Y or X meets after Y.
The overlaps operator can also be invoked without the before or after suffix, indicating that any overlap should return true.
Note that to use these operators, the intervals must be of the same point type. For example, it is invalid to compare an interval of dates or times with an interval of numbers.
In addition to the interval comparison operators described above, CQL allows various timing relationships to be expressed by directly accessing the start and end boundaries of the intervals involved. For example:
X starts before start Y
This expression returns true if the start of X is before the start of Y.
In addition, timing phrases allow the use of time durations to offset the relationship. For example:
X starts 3 days before start Y
This returns true if the start of X is equal to three days before the start of Y. Timing phrases can also include less than, more than, or less and or more to determine how the time duration is interpreted. For example:
X starts 3 days or less before start Y
X starts less than 3 days before start Y
X starts 3 days or more before start Y
X starts more than 3 days before start Y
The first expression returns true if the start of X is within the interval beginning three days before the start of Y and ending just before the start of Y. The second expression returns true if the start of X is within the interval beginning just after three days before the start of Y and ending just before the start of Y. The third expression returns true if the start of X is three days or more before the start of Y. And the fourth expression returns true if the start of X is more than three days before the start of Y.
Timing phrases can also support inclusive comparisons using on or and or on syntax. For example:
X starts 3 days or less before or on start Y
X starts less than 3 days on or after end Y
The first expression returns true if the start of X is within the interval beginning three days before the start of Y and ending exactly on the start of Y. The second expression returns true if the start of X is within the interval beginning exactly on the end of Y and ending less than 3 days after the end of Y.
Note that on or and or on can be used with both before and after. This flexibility is to allow for natural phrasing.
Timing phrases also allow the use of within to establish a range for comparison:
X starts within 3 days of start Y
This expression returns true if the start of X is in the interval beginning three days before the start of Y and ending 3 days after the start of Y.
In addition, if either comparand is a Date or Time value, rather than an interval, it can be used in any of the timing phrases without the boundary access modifiers:
dateTimeX within 3 days of dateTimeY
In other words, the timing phrases in general compare two quantities, either of which may be an date- or time-valued interval or date or time point value, and the boundary access modifiers can be added to a given timing phrase to access the boundary of an interval.
The following table describes the operators that can be used to construct timing phrases:
| Operator | Beginning Boundary (starts/ends) | Ending Boundary (start/end) | Duration Offset | Or Less/ Or More |
Or Before/ Or After | Less Than/ More Than | Or On/ On Or |
|---|---|---|---|---|---|---|---|
| same as | yes | yes | no | no | yes | no | no |
| before | yes | yes | yes | yes | no | yes | yes |
| after | yes | yes | yes | yes | no | yes | yes |
| within…of | yes | yes | required | no | no | no | no |
| during | yes | no | no | no | no | no | no |
| includes | no | yes | no | no | no | no | no |
Table 2‑R - The operators that can be used to construct timing phrases
A yes in the Beginning Boundary column indicates that the operator can be preceded by starts or ends if the left comparand is an interval.
A yes in the Ending Boundary column indicates that the timing phrase can be succeeded by a start or end if the right comparand is an interval.
A yes in the duration offset column indicates that the timing phrase may include a duration offset.
A yes in the Or Less/OrMore column indicates that the timing phrase may include an or less/or more modifier.
A yes in the Or Before/Or After column indicates that the timing phrase may include an or before/or after modifier.
A yes in the Less Than/More Than column indicates that the timing phrase may include a less than/more than modifier.
And finally, a yes in the Or On/On Or column indicates that the timing phrase may include a on or/or on modifier.
In addition, to support more natural-language phrasing of timing operations, the keyword occurs may appear anywhere that starts or ends can appear in the timing phrase. For example:
X occurs within 3 days of start Y
The occurs keyword is both optional and ignored by CQL. It is only provided to enable more natural phrasing.
CQL provides several operators that can be used to combine existing intervals into new intervals. For example:
Interval[1, 3] union Interval[3, 6]
This expression returns the interval [1, 6]. Note that interval union is only defined if the arguments overlap or meet.
Interval intersect results in the overlapping portion of two intervals:
Interval[1, 4] intersect Interval[3, 6]
This expression results in the interval [3, 4].
Interval except computes the difference between two intervals. In other words, the result is points in the left operand that are not in the right operand. For example:
Interval[1, 4] except Interval[3, 6]
This expression results in the interval [1, 2]. Note that except is only defined for cases that result in a well-formed interval. For example, if either argument properly includes the other and does not start or end it, the result of subtracting one interval from the other would be two intervals, and the result is thus not defined and results in null.
The following diagrams depict the union, intersect, and except operators for intervals:
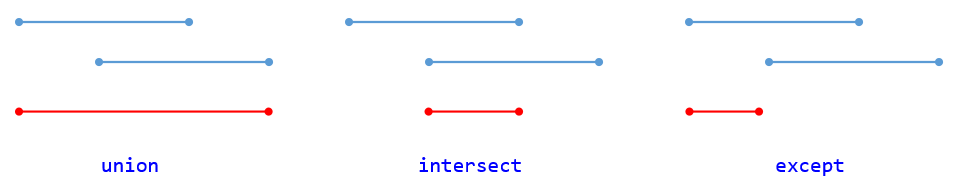
Figure 2‑D - The union, intersect, and except operators for intervals
Because CQL supports date and time values with varying levels of precision, intervals of dates and times can potentially involve imprecise date and time values. To ensure well-defined intervals and consistent semantics, date and time intervals are always considered to contain the full set of values contained by the boundaries of the interval. For example, the following interval expression contains all the instants of time, to the millisecond precision, beginning at midnight on January 1st, 2014, and ending at midnight on January 1st, 2015:
Interval[DateTime(2014, 1, 1, 0, 0, 0, 0), DateTime(2015, 1, 1, 0, 0, 0, 0)]
However, if the boundaries of the interval are specified to a lower precision, the interval is interpreted as beginning at some time within the most specified precision, and ending at some time within the most specified precision. For example, the following interval expression contains all the instants of time, to the millisecond precision, beginning sometime in the year 2014, and ending sometime in the year 2015:
Interval[Date(2014), Date(2015)]
When calculating the duration of the interval, this imprecision will in general result in an uncertainty, just as it does when calculating the duration between two imprecise date or time values.
In addition, the boundaries may even be specified to different levels of precision. For example, the following interval expression contains all the instants of time, to the millisecond precision, beginning sometime in the year 2014, and ending sometime on January 1st, 2015:
Interval[Date(2014), Date(2015, 1, 1)]
Note that when calculating duration, just like date and time comparison calculations, seconds and milliseconds are considered a single precision with decimal semantics.
Clinical information is almost always stored, collected, and presented in terms of lists of information. As a result, the expression of clinical knowledge almost always involves dealing with lists of information in some way. The query construct already discussed provides a powerful mechanism for dealing with lists, but CQL also provides a comprehensive set of operations for dealing with lists in other ways. These operations can be broadly categorized into three groups:
Although the most common source of lists in CQL is the retrieve expression, lists can also be constructed directly using the list selector discussed in List Values.
The elements of a list can be accessed using the indexer ([]) operator. For example:
X[0]
This expression accesses the first element of the list X.
If a list contains a single element, the singleton from operator can be used to extract it:
singleton from { 1 }
singleton from { 1, 2, 3 }
Using singleton from on a list with multiple elements will result in a run-time error.
The index of an element e in a list X can be obtained using the IndexOf operator. For example:
IndexOf({'a', 'b', 'c' }, 'b') // returns 1
If the element is not found in the list, IndexOf returns -1.
In addition, the number of elements in a list can be determined using the Count operator. For example:
Count({ 1, 2, 3, 4, 5 })
This expression returns the value 5.
Membership in lists can be determined using the in operator and its inverse, contains:
{ 1, 2, 3, 4, 5 } contains 4
4 in { 1, 2, 3, 4, 5 }
The exists operator can be used to test whether a list contains any elements:
exists ( { 1, 2, 3, 4, 5 } )
exists ( { } )
The first expression returns true, while the second expression returns false. This is most often used in queries to determine whether a query returns any results.
The First and Last operators can be used to retrieve the first and last elements of a list. For example:
First({ 1, 2, 3, 4, 5 })
Last({ 1, 2, 3, 4, 5 })
First({})
Last({})
In the above examples, the first expression returns 1, and the second expression returns 5. The last two expressions both return null since there is no first or last element of an empty list. Note that the First and Last operators refer to the position of an element in the list, not the temporal relationship between elements. In order to extract the earliest or latest elements of a list, the list would first need to be sorted appropriately.
In addition, to provide consistent and intuitive semantics when dealing with lists, whenever an operation needs to determine whether or not a given list contains an element (including list operations discussed later such as intersect, except, and distinct), CQL uses equality semantics.
In addition to list equality, already discussed in Comparison Operators, lists can be compared using the following operators:
| Operator | Description |
|---|---|
| X includes Y | Returns true if every element in list Y is also in list X, using equality semantics |
| X properly includes Y | Returns true if every element in list Y is also in list X and list X has more elements than list Y |
| X included in Y | Returns true if every element in list X is also in list Y, using equality semantics |
| X properly included in Y | Returns true if every element in list X is also in list Y, and list Y has more elements than list X |
Table 2‑S - The operators that can be used for list comparisons
{ 1, 2, 3, 4, 5 } includes { 5, 2, 3 }
{ 5, 2, 3 } included in { 1, 2, 3, 4, 5 }
{ 1, 2, 3, 4, 5 } includes { 4, 5, 6 }
{ 4, 5, 6 } included in { 1, 2, 3, 4, 5 }
In the above examples, the first two expressions are true, but the last two expressions are false.
The properly modifier ensures that the lists are not the same list. For example:
{ 1, 2, 3 } includes { 1, 2, 3 }
{ 1, 2, 3 } included in { 1, 2, 3 }
{ 1, 2, 3 } properly includes { 1, 2, 3 }
{ 1, 2, 3 } properly included in { 1, 2, 3 }
{ 1, 2, 3, 4, 5 } properly includes { 2, 3, 4 }
{ 2, 3, 4 } properly included in { 1, 2, 3, 4, 5 }
In the above examples, the first two expressions are true, but the next two expressions are false, because although each element is in the other list, the properly requires that one list be strictly larger than the other, as in the last two expressions.
Note that during is a synonym for included in and can be used anywhere included in is allowed. The syntax allows for both keywords to enable more natural phrasing of time-based relationships depending on context.
CQL provides several operators for computing new lists from existing ones.
To eliminate duplicates from a list, use the distinct operator:
distinct { 1, 1, 2, 2, 3, 4, 5 }
This example returns:
{ 1, 2, 3, 4, 5 }
Note that the distinct operator uses equality semantics (~) to detect duplicates. Because equality is defined for all types, this means that distinct can be used on lists with elements of any type. In particular, duplicates can be eliminated from lists of tuples, and the operation will use tuple equality (i.e. tuples are equal if they have the same type and value (or no value) for each element of the same name).
To combine all the elements from multiple lists, use the union operator:
{ 1, 2, 3 } union { 3, 4, 5 }
This example returns:
{ 1, 2, 3, 4, 5 }
Note that duplicates are eliminated in the result of a union.
To compute only the common elements from multiple lists, use the intersect operator:
{ 1, 2, 3 } intersect { 3, 4, 5 }
This example returns:
{ 3 }
To remove the elements in one list from another list, use the except operator:
{ 1, 2, 3 } except { 3, 4, 5 }
This example returns:
{ 1, 2 }
The following diagrams depict the union, intersect, and except operators:
Figure 2‑E - The union, intersect, and except operators for lists
As with the distinct operator, the intersect, and except operators use the equality operator to determine when two elements are the same. In particular, this means that nulls in the input to a distinct will be preserved in the output.
Because lists may contain lists, CQL provides a flatten operation that can flatten lists of lists:
flatten { { 1, 2, 3 }, { 3, 4, 5 } }
This example returns:
{ 1, 2, 3, 3, 4, 5 }
Note that unlike the union operator, duplicate elements are retained in the result.
Note also that flatten only flattens one level, it is not recursive.
Although the examples in this section primarily use lists of integers, these operators work on lists with elements of any type.
Most list operators in CQL operate on lists of any type, but for lists of intervals, CQL supports a collapse operator that determines the list of unique intervals from a given list of intervals. Consider the following intervals:
Figure 2‑F - Example input intervals to illustrate the behavior of the the collapse operator
If we want to determine the total duration covered by these intervals, we cannot simply use the distinct operator, because each of these intervals is different. Yet two of them overlap, so they cover part of the same range. We also can’t simply perform an aggregate union of the intervals because some of them don’t overlap, so there isn’t a single interval that covers the entire range.
The solution is the collapse operator which returns the set of intervals that completely cover the ranges covered by the inputs:

Figure 2‑G - Example output intervals to illustrate the behavior of the collapse operator
Now, when we take the Sum of the durations of the intervals, we are guaranteed not to overcount any particular point in the ranges that may have been included in multiple intervals in the original set.
In addition, CQL supports an expand operator that determines the list of intervals of size per from a given list of intervals. This operator is important for calculations involving sets of intervals, in particular for performing calculations such as average daily dose in a given timeframe. Part of this calculation involves determining the dosage on each day. For example, assuming a definition EffectivePeriods contains the list of intervals corresponding to prescription periods:
expand EffectivePeriods per day
This expression would result in the list of day intervals, one for each day in the intervals in the input.
Summaries and statistical calculations are a critical aspect of being able to represent clinical knowledge, especially in the quality measurement domain. Thus, CQL includes a comprehensive set of aggregate operators.
Aggregate operators are defined to work on lists of values. For example, the Count operator works on any list:
Count([Encounter])
This expression returns the number of Encounter events.
The Sum operator, however, works only on lists of numbers or lists of quantities:
Sum({ 1, 2, 3, 4, 5 })
This example results in the sum 15. To sum the results of a list of Observation values, for example, a query is used to extract the values to be summed:
Sum([Observation] R return R.result)
In general, nulls encountered during aggregation are ignored, and with the exception of Count, AllTrue, and AnyTrue, the result of the invocation of an aggregate on an empty list is null. Count is defined to return 0 for an empty list. AllTrue is defined to return true for an empty list, and AnyTrue is defined to return false for an empty list. In addition, operations that cause arithmetic overflow or underflow, or otherwise cannot be performed (such as division by 0) will result in null, rather than a run-time error.
The following table lists the aggregate operators available in CQL:
| Operator | Description |
|---|---|
| Count | Returns the number of elements in its argument |
| Sum | Returns the numeric sum of the elements in the list |
| Min | Returns the minimum value of any element in the list |
| Max | Returns the maximum value of any element in the list |
| Avg | Returns the numeric average (mean) of all elements in the list |
| Median | Returns the statistical median of all elements in the list |
| Mode | Returns the most frequently occurring value in the list |
| StdDev | Returns the sample standard deviation (square root of the sample variance) of the elements in the list |
| PopStdDev | Returns the population standard deviation (square root of the population variance) of the elements in the list |
| Variance | Returns the sample variance (average distance of the data elements from the sample mean, corrected for bias by using N-1 as the denominator in the mean calculation, rather than N) of the elements in the list |
| PopVariance | Returns the population variance (average distance of the data elements from the population mean) of the elements in the list |
| AllTrue | Returns true if all the elements in the list are true, false otherwise |
| AnyTrue | Returns true if any of the elements in the list are true, false otherwise |
| GeometricMean | Return the geometric mean of the non-null elements in the list |
| Product | Returns the geometric product of the elements in the list |
Table 2‑T - The aggregate operators available in CQL
CQL supports several operators for use with the various clinical types in the language.
All quantities in CQL have unit and value components, which can be accessed in the same way as properties. For example:
define "IsTall": height.units = 'm' and height.value > 2
However, because CQL supports operations on quantities directly, this expression could be simplified to:
define "IsTall": height > 2 'm'
This formulation also has the advantage of allowing for the case that the actual value of height is expressed in inches.
CQL supports the standard comparison operators (= != ~ !~ < <= > >=) and the standard arithmetic operators (+ - * /) for quantities. In addition, aggregate operators that utilize these basic comparisons and computations are also supported, such as Min, Max, Sum, etc.
Note that complete support for unit conversion for all valid UCUM units would be ideal, but practical CQL implementations will likely provide support for a subset of units for commonly used clinical dimensions. At a minimum, however, a CQL implementation must respect units and return null if it is not capable of normalizing the quantities involved in a given expression to a common unit. Implementations should issue a run-time warning in these cases as well.
All ratios in CQL have numerator and denominator components, which can be accessed in the same way as properties. For example:
define "TitreRatio": 1:128
define "TitreNumerator": TitreRatio.numerator // 1
CQL supports the equality operators (= != ~ !~) for ratios, as well as conversion from strings to ratios using the ToString and ToRatio functions. Other operations on ratios must be specified by accessing the numerator or denominator components. For equality, ratios are considered equal if they have the same value for the numerator and denominator, using quantity equality semantics. Two ratios are considered equivalent if they represent the same ratio:
define "RatioEqualTrue": 1:100 = 1:100
define "RatioEqualFalse": 1:100 = 10:1000
define "RatioEquivalentTrue": 1:100 ~ 10:1000
Note that the relative comparison operators (>, >=, <, <=) are specifically not supported for ratios because in healthcare settings, it is often not possible to correctly interpret the meaning of a ratio without the relevant context, resulting in the risk of expressions involving ratio comparisons meaning the exact opposite of what the author intended. Relative comparisons may still be performed explicitly, either by accessing the numerator and denominator components of the ratio directly, or by using the ToQuantity operator to convert the ratio to a decimal quantity.
In addition to providing first-class valueset and codesystem constructs, CQL provides operators for retrieving and testing membership in valuesets and codesystems:
valueset "Acute Pharyngitis": 'urn:oid:2.16.840.1.113883.3.464.1003.102.12.1011'
define "InPharyngitis": SomeCodeValue in "Acute Pharyngitis"
These statements define the InPharyngitis expression as true if the Code-valued expression SomeCodeValue is in the "Acute Pharyngitis" valueset.
Note that valueset membership is based strictly on the definition of equivalence (i.e. two codes are the same if they have the same value for the code and system elements, ignoring display and version). CQL explicitly forbids the notion of terminological equivalence among codes being used in this context.
Note that this operator can be invoked with a code argument of type String, Code, and Concept. When invoked with a Concept, the result is true if any Code in the Concept is a member of the given valueset.
A common terminological operation involves determining whether a given concept is implied, or subsumed by another. This operation is generally referred to as subsumption and although useful, is deliberately omitted from this specification. The reason for this omission different terminology systems generally provide different mechanisms for defining and interpreting subsumption relationships. As a result, specifying how that occurs is beyond the scope of CQL at this time. This is not to say that a specific library of subsumption operators could not be provided and broadly adopted and used, only that the CQL specification does not prescribe the semantics of that operation.
To support determination of patient age consistently throughout quality logic, CQL defines several age-related operators:
| Operator | Description |
|---|---|
| AgeInYearsAt(X) | Determines the age of the patient in years as of the date or datetime X |
| AgeInYears() | Determines the age of the patient in years as of today. Equivalent to AgeInYearsAt(Today()) |
| AgeInMonthsAt(X) | Determines the age of the patient in months as of the date or datetime X |
| AgeInMonths() | Determines the age of the patient in months as of today. Equivalent to AgeInMonthsAt(Today()) |
| AgeInWeeksAt(X) | Determines the age of the patient in weeks as of the date or datetime X |
| AgeInWeeks() | Determines the age of the patient in weeks as of now. Equivalent to AgeInWeeksAt(Now()) |
| AgeInDaysAt(X) | Determines the age of the patient in days as of the date or datetime X |
| AgeInDays() | Determines the age of the patient in days as of now. Equivalent to AgeInDaysAt(Now()) |
| AgeInHoursAt(X) | Determines the age of the patient in hours as of the datetime X |
| AgeInHours() | Determines the age of the patient in hours as of now. Equivalent to AgeInHoursAt(Now()) |
| CalculateAgeInYearsAt(D, X) | Determines the age of a person with birth date or datetime D in years as of the date or datetime X |
| CalculateAgeInYears(D) | Determines the age of a person with birth date or datetime D in years as of today/now. Equivalent to CalculateAgeInYearsAt(D, Today()) or CalculateAgeInYearsAt(D, Now()) |
| CalculateAgeInMonthsAt(D, X) | Determines the age of a person with birth date or datetime D in months as of the date or datetime X |
| CalculateAgeInMonths(D) | Determines the age of a person with birth date or datetime D in months as of today/now. Equivalent to CalculateAgeInMonthsAt(D, Today()) or CalculateAgeInMonthsAt(D, Now()) |
| CalculateAgeInWeeksAt(D, X) | Determines the age of a person with birth date or datetime D in weeks as of the date or datetime X |
| CalculateAgeInWeeks(D) | Determines the age of a person with birth date or datetime D in weeks as of today. Equivalent to CalculateAgeInWeeksAt(D, Today()) or CalculateAgeInWeeksAt(D, Now()) |
| CalculateAgeInDaysAt(D, X) | Determines the age of a person with birth date or datetime D in days as of the date or datetime X |
| CalculateAgeInDays(D) | Determines the age of a person with birth date or datetime D in days as of now. Equivalent to CalculateAgeInDaysAt(D, Today()) or CalculateAgeInDaysAt(D, Now()) |
| CalculateAgeInHoursAt(D, X) | Determines the age of a person with birth datetime D in hours as of the datetime X |
| CalculateAgeInHours(D) | Determines the age of a person with birth datetime D in hours as of now. Equivalent to CalculateAgeInHoursAt(D, Now()) |
Table 2‑U - The age related operators available in CQL
These operators calculate age using calendar duration.
Note that when Age operators are invoked in an unspecified context, the result is a list of patient ages, not a single age for the current patient.
This section provides a walkthrough of the process of developing shareable artifact logic using CQL. The walkthrough is based on the development of the logic for a simplified Chlamydia Screening quality measure and its associated decision support rule.
Although the examples in this guide focus on populations of patients, CQL can also be used to express non-patient-based artifacts such as episode-of-care measures, or organizational measures such as number of staff in a facility. For examples of these types of measures, see the Examples included with this specification.
The running example for this walkthrough is a simplification of CMS153, version 2, Chlamydia Screening for Women. The original QDM for this measure was simplified by including only references to the following QDM data elements:
Laboratory Test, Order
This results in the following QDM:
Note that these simplifications result in a measure that is not clinically relevant, and the result of this walkthrough is in no way intended to be used in a production scenario. The walkthrough is intended only to demonstrate how CQL can be used to construct shareable clinical logic.
As an aside, one of the simplifications made to the QDM presented above is the removal of the notion of occurrencing. Readers familiar with that concept as defined in QDM should be aware that CQL by design does not include this notion. CQL queries are expressive enough that the correlation accomplished by occurrencing in QDM is not required in CQL.
The following table lists the QDM data elements involved and their mappings to the QUICK data structures:
| QDM Data Element | QUICK Equivalent |
|---|---|
| Patient Characteristic Birthdate | Patient.birthDate |
| Patient Characteristic Sex | Patient.gender |
| Diagnosis | Condition |
| Laboratory Test, Order | DiagnosticOrder |
| Laboratory Test, Result | DiagnosticReport |
Table 2‑V - QDM Data elements and their mapping to QUICK data structures
Note that the specific mapping to the QUICK data structures is beyond the scope of this walkthrough; it is only provided here to demonstrate the link back to the original QDM.
Note also that the use of the QDM as a starting point was deliberately chosen to provide familiarity and is not a general requirement for building CQL. Artifact development could also begin directly from clinical guidelines expressed in other formats or directly from relevant clinical domain expertise. Using the QDM provides a familiar way to establish the starting requirements.
For clinical quality measures, the CQL library simply provides a repository for definitions of the populations involved. CQL is intended to support both CQM and CDS applications, so it does not contain quality measure specific constructs. Rather, the containing artifact definition, such as an HQMF document, would reference the appropriate criteria expression by name within the CQL document.
With that in mind, a CQL library intended to represent the logic for a CQM must expose at least the population definitions needed for the measure. In this case, we have criteria definitions for:
Denominator
Looking at the Initial Population, we have the demographic criteria:
For the age criteria, CQL defines an AgeInYearsAt operator that returns the age of the patient as of a given date or datetime. Using this operator, and assuming a measurement period of the year 2013, we can express the patient age criteria as:
AgeInYearsAt(@2013-01-01) >= 16 and AgeInYearsAt(@2013-01-01) < 24
In order to use the AgeInYearsAt operator, we must be in the Patient context:
context Patient
In addition, to allow this criteria to be referenced both within the CQL library by other expressions, as well as potentially externally, we need to assign an identifier:
define "InInitialPopulation":
AgeInYearsAt(@2013-01-01) >= 16 and AgeInYearsAt(@2013-01-01) < 24
Because the quality measure is defined over a measurement period, and many, if not all, of the criteria we build will have some relationship to this measurement period, it is useful to define the measurement period directly:
define "MeasurementPeriod": Interval[
@2013-01-01T00:00:00.0,
@2014-01-01T00:00:00.0
)
This establishes MeasurementPeriod as the interval beginning precisely at midnight on January 1st, 2013, and ending immediately before midnight on January 1st, 2014. We can now use this in the age criteria:
define "InInitialPopulation":
AgeInYearsAt(start of MeasurementPeriod) >= 16
and AgeInYearsAt(start of MeasurementPeriod) < 24
Even more useful would be to define MeasurementPeriod as a parameter that can be provided when the quality measure is evaluated. This allows us to use the same logic to evaluate the quality measure for different years. So instead of using a define statement, we have:
parameter MeasurementPeriod default Interval[
@2013-01-01T00:00:00.0,
@2014-01-01T00:00:00.0
)
The InInitialPopulation expression remains the same, but it now accesses the value of the parameter instead of the define statement.
Since we are in the Patient context and have access to the attributes of the Patient (as defined by the data model in use), the gender criteria can be expressed as follows:
Patient.gender in "Female Administrative Sex"
This criteria requires that the gender attribute of a Patient be a code that is in the valueset identified by "Female Administrative Sex". Of course, this requires the valueset definition:
valueset "Female Administrative Sex": 'urn:oid:2.16.840.1.113883.3.560.100.2'
Putting it all together, we now have:
library CMS153_CQM version '2'
using QUICK
parameter MeasurementPeriod default Interval[
@2013-01-01T00:00:00.0,
@2014-01-01T00:00:00.0
)
valueset "Female Administrative Sex": 'urn:oid:2.16.840.1.113883.3.560.100.2'
context Patient
define "InInitialPopulation":
AgeInYearsAt(start of MeasurementPeriod) >= 16
and AgeInYearsAt(start of MeasurementPeriod) < 24
and Patient.gender in "Female Administrative Sex"
The next step is to capture the rest of the initial population criteria, beginning with this QDM statement:
"Diagnosis: Other Female Reproductive Conditions" overlaps with "Measurement Period"
This criteria has three main components:
The valueset involved
Using the mapping to QUICK, the equivalent retrieve in CQL is:
[Condition: "Other Female Reproductive Conditions"] C
where Interval[C.onsetDateTime, C.abatementDate] overlaps MeasurementPeriod
This query retrieves all Condition events for the patient with a code in the "Other Female Reproductive Conditions" valueset that overlap the measurement period. Note that in order to use the overlaps operator, we had to construct an interval from the onsetDateTime and abatementDate elements. If the model had an interval-valued “effective time” element, we could have used that directly, rather than having to construct an interval.
The result of the query is a list of conditions. However, this isn’t quite what the QDM statement is actually saying. In QDM, the statement can be read loosely as “include patients in the initial population that have at least one active diagnosis from the Other Female Reproductive Conditions valueset.” To express this in CQL, what we really need to ask is whether the equivalent retrieve above returns any results, which is accomplished with the exists operator:
exists ([Condition: "Other Female Reproductive Conditions"] C
where Interval[C.onsetDateTime, C.abatementDate] overlaps MeasurementPeriod)
Incorporating the next QDM statement:
OR: "Diagnosis: Genital Herpes" overlaps with "Measurement Period"
We have:
exists ([Condition: "Other Female Reproductive Conditions"] C
where Interval[C.onsetDateTime, C.abatementDate] overlaps MeasurementPeriod
)
or exists ([Condition: "Genital Herpes"] C
where Interval[C.onsetDateTime, C.abatementDate] overlaps MeasurementPeriod
)
Which we can repeat for each Diagnosis, Active statement. Note here that even though we are using the same alias, C, for each query, they do not clash because they are only declared within their respective queries (or scopes).
Next, we get to the Laboratory Test statements:
We use the same approach. The equivalent retrieve for the first criteria is:
exists ([DiagnosticOrder: "Pregnancy Test"] O
where Last(O.event E where E.status = 'completed' sort by date).date
during MeasurementPeriod)
This query is retrieving pregnancy tests that were completed within the measurement period. Because diagnostic orders do not have a top-level completion date, the date must be retrieved with a nested query on the events associated with the diagnostic orders. The nested query returns the set of completed events ordered by their completion date, the Last invocation returns the most recent of those events, and the .date accessor retrieves the value of the date element of that event.
And finally, translating the rest of the statements allows us to express the entire initial population as:
define "InInitialPopulation":
AgeInYearsAt(start of MeasurementPeriod) >= 16
and AgeInYearsAt(start of MeasurementPeriod) < 24
and Patient.gender in "Female Administrative Sex"
and
(
exists ([Condition: "Other Female Reproductive Conditions"] C
where Interval[C.onsetDateTime, C.abatementDate] overlaps MeasurementPeriod)
or exists ([Condition: "Genital Herpes"] C
where Interval[C.onsetDateTime, C.abatementDate] overlaps MeasurementPeriod)
or exists ([Condition: "Genococcal Infections and Venereal Diseases"] C
where Interval[C.onsetDateTime, C.abatementDate] overlaps MeasurementPeriod)
...
or exists ([DiagnosticOrder: "Pregnancy Test"] O
where Last(O.event E where E.status = 'completed' sort by date).date
during MeasurementPeriod)
...
)
Because CQL allows any number of define statements with any identifiers, we can structure the logic of the measure to communicate more meaning to readers of the logic. For example, if we look at the description of the quality measure:
Percentage of women 16-24 years of age who were identified as sexually active and who had at least one test for chlamydia during the measurement period. ____________________________________________________
it becomes clear that the intent of the Diagnosis, Active and Laboratory Test, Order QDM criteria is to attempt to determine whether or not the patient is sexually active. Of course, we’re dealing with a simplified measure and so much of the nuance of the original measure is lost; the intent here is not to determine whether this is in fact a good way in practice to determine whether or not a patient is sexually active, but rather to show how CQL can be used to help communicate aspects of the meaning of quality logic that would otherwise be lost or obscured.
With this in mind, rather than expressing the entire initial population as a single define, we can break it up into several more understandable and more meaningful expressions:
define "Patient16To23AndFemale":
AgeInYearsAt(start of MeasurementPeriod) >= 16
and AgeInYearsAt(start of MeasurementPeriod) < 24
and Patient.gender in "Female Administrative Sex"
define "SexuallyActive":
exists ([Condition: "Other Female Reproductive Conditions"] C
where Interval[C.onsetDateTime, C.abatementDate] overlaps MeasurementPeriod)
or exists ([Condition: "Genital Herpes"] C
where Interval[C.onsetDateTime, C.abatementDate] overlaps MeasurementPeriod)
or exists ([Condition: "Genococcal Infections and Venereal Diseases"] C
where Interval[C.onsetDateTime, C.abatementDate] overlaps MeasurementPeriod)
...
or exists ([DiagnosticOrder: "Pregnancy Test"] O
where Last(O.event E where E.status = 'completed' sort by date).date
during MeasurementPeriod)
...
define "InInitialPopulation":
Patient16To23AndFemale and SexuallyActive
Restructuring the logic in this way not only simplifies the expressions involved and makes them more understandable, but it clearly communicates the intent of each group of criteria.
Note that the InInitialPopulation expression is returning a boolean value indicating whether or not the patient should be included in the initial population.
The next population to define is the denominator, which in our simplified expression of the measure is the same as the initial population. Because the intent of the CQL library for a quality measure is only to define the logic involved in defining the populations, it is assumed that the larger context (such as an HQMF artifact definition) is providing the overall structure, including the meaning of the various populations involved. As such, each population definition with the CQL library should include only those aspects that are unique to that population.
For example, the actual criteria for the denominator is that the patient is in the initial population. But because that notion is already implied by the definition of a population measure (that the denominator is a subset of the initial population), the CQL for the denominator should simply be:
define "InDenominator": true
This approach to defining the criteria is more flexible from the perspective of actually evaluating a quality measure, but it may be somewhat confusing when looking at the CQL in isolation.
Note that the approach to defining population criteria is established by quality measure-specific guidance outside the scope of this specification. We follow this approach here just for simplicity.
Following this approach then, we express the numerator as:
define "InNumerator":
exists ([DiagnosticReport: "Chlamydia Screening"] R
where R.issued during MeasurementPeriod and R.result is not null)
Note that the R.result is not null condition is required because the original QDM statement involves a test for the presence of an attribute:
"Laboratory Test, Result: Chlamydia Screening (result)" during "Measurement Period"
The (result) syntax indicates that the item should only be included if there is some value present for the result attribute. The equivalent expression in CQL is the null test.
Finally, putting it all together, we have a complete, albeit simplified, definition of the logic involved in defining the population criteria for a measure:
library CMS153_CQM version '2'
using QUICK
valueset "Female Administrative Sex": 'urn:oid:2.16.840.1.113883.3.560.100.2'
...
parameter MeasurementPeriod default Interval[
@2013-01-01T00:00:00.0,
@2014-01-01T00:00:00.0
)
context Patient
define "Patient16To23AndFemale":
AgeInYearsAt(start of MeasurementPeriod) >= 16
and AgeInYearsAt(start of MeasurementPeriod) < 24
and Patient.gender in "Female Administrative Sex"
define "SexuallyActive":
exists ([Condition: "Other Female Reproductive Conditions"] C
where Interval[C.onsetDateTime, C.abatementDate] overlaps MeasurementPeriod)
or exists ([Condition: "Genital Herpes"] C
where Interval[C.onsetDateTime, C.abatementDate] overlaps MeasurementPeriod)
or exists ([Condition: "Genococcal Infections and Venereal Diseases"] C
where Interval[C.onsetDateTime, C.abatementDate] overlaps MeasurementPeriod)
...
or exists ([DiagnosticOrder: "Pregnancy Test"] O
where Last(O.event E where E.status = 'completed').date
during MeasurementPeriod)
...
define "InInitialPopulation":
Patient16To23AndFemale and SexuallyActive
define "InDenominator": true
define "InNumerator":
exists ([DiagnosticReport: "Chlamydia Screening"] R
where R.issued during MeasurementPeriod and R.result is not null)
Using the same simplified measure expression as a basis, we will now build a complementary clinical decision support rule that can provide guidance at the point-of-care. In general, when choosing what decision support artifacts will be most complementary to a given quality measure, several factors must be considered including EHR and practitioner workflows, data availability, the potential impacts of the guidance, and many others.
Though these are all important considerations and should not be ignored, they are beyond the scope of this document, and for the purposes of this walkthrough, we will assume that a point-of-care decision support intervention has been selected as the most appropriate artifact.
When building a point-of-care intervention based on a quality measure, several specific factors must be considered.
First, quality measures typically contain logic designed to identify a specific setting in which a particular aspect of health quality is to be measured. This usually involves identifying various types of encounters. By contrast, a point-of-care decision support artifact is typically written to be evaluated in a specific context, so the criteria around establishing the setting can typically be ignored. For the simplified measure we are dealing with, the encounter setting criteria were removed as part of the simplification.
Second, quality measures are designed to measure quality within a specific timeframe, whereas point-of-care measures don’t necessarily have those same restrictions. For example, the diagnoses in the current example are restricted to the measurement period. There may be some clinically relevant limit on the amount of time that should be used to search for diagnoses, but it does not necessarily align with the measurement period. For the purposes of this walkthrough, we will make the simplifying assumption that any past history of the relevant diagnoses is a potential indicator of sexual activity.
Third, quality measures are written retrospectively, that is, they are always dealing with events that occurred in the past. By contrast, decision support artifacts usually involve prospective, as well as retrospective data. As such, different types of clinical events may be involved, such as planned or proposed events.
Fourth, quality measures, especially proportion measures, typically express the numerator criteria as a positive result, whereas the complementary logic for a decision support rule would be looking for the absence of the criteria. For example, the criteria for membership in the numerator of the measure we are using is that the patient has had a Chlamydia screening within the measurement period. For the point-of-care intervention, that logic becomes a test for patients that have not had a Chlamydia screening.
And finally, although present in some quality measures, many do not include criteria to determine whether or not there is some practitioner- or patient-provided reason for not taking some course of action. This is often due to the lack of a standardized mechanism for describing this criteria and is usually handled on a measure-by-measure basis as part of actually evaluating measures. Regardless of the reason, because a point-of-care intervention has the potential to interrupt a practitioner workflow, the ability to determine whether or not a course of action being proposed has already been considered and rejected is critical.
With these factors in mind, and using the CQL for the measure we have already built, deriving a point-of-care intervention is fairly straightforward.
To begin with, we are using the same data model, QUICK, the same valueset declarations, and the same context:
library CMS153_CDS version '2'
using QUICK
codesystem "SNOMED": 'http://snomed.info/sct'
valueset "Female Administrative Sex": 'urn:oid:2.16.840.1.113883.3.560.100.2'
...
context Patient
Note that we are not using the MeasurementPeriod parameter. There are other potential uses for parameters within the point-of-care intervention (for example, to specify a threshold for how far back to look for a Chlamydia screening), but we are ignoring those aspects for the purposes of this walkthrough.
For the Patient16To23AndFemale criteria, we are then simply concerned with female patients between the ages of 16 and 24, so we change the criteria to use the AgeInYears, rather than the AgeInYearsAt operator, to determine the patient’s age as of today:
define "Patient16To23AndFemale":
AgeInYears() >= 16 and AgeInYears() < 24
and Patient.gender in "Female Administrative Sex"
Similarly for the SexuallyActive criteria, we remove the relationship to the measurement period:
define "SexuallyActive":
exists ([Condition: "Other Female Reproductive Conditions"])
or exists ([Condition: "Genital Herpes"])
or exists ([Condition: "Genococcal Infections and Venereal Diseases"])
...
or exists ([DiagnosticOrder: "Pregnancy Test"])
...
For the numerator, we need to invert the logic, so that we are looking for patients that have not had a Chlamydia screening, and rather than the measurement period, we are looking for the test within the last year:
not exists ([DiagnosticReport: "Chlamydia Screening"] R
where R.issued during Interval[Today() - 1 years, Today()]
and R.result is not null)
In addition, we need a test to ensure that the patient does not have a planned Chlamydia screening:
not exists ([ProcedureRequest: "Chlamydia Screening"] R
where R.orderedOn same day or after Today())
And to ensure that there is not a reason for not performing a Chlamydia screening:
not exists ([Observation: "Reason for not performing Chlamydia Screening"])
We combine those into a NoScreening criteria:
define "NoScreening":
not exists ([DiagnosticReport: "Chlamydia Screening"] R
where R.issued during Interval[Today() - 1 years, Today()]
and R.result is not null)
and not exists ([ProcedureRequest: "Chlamydia Screening"] R
where R.orderedOn same day or after Today())
and not exists ([Observation: "Reason for not performing Chlamydia Screening"])
And finally, we provide an overall condition that indicates whether or not this intervention should be triggered:
define "NeedScreening": Patient16To23AndFemale and SexuallyActive and NoScreening
Now, this library can be referenced by a CDS knowledge artifact, and the condition can reference the NeedScreening expression, which loosely reads: the patient needs screening if they are in the appropriate demographic, have indicators of sexual activity, and do not have screening.
In addition, this library should include the proposal aspect of the intervention. In general, the overall artifact definition (such as a CDS KAS artifact) would define what actions should be performed when the condition is satisfied. Portions of that action definition may reference other expressions within a CQL library, just as the HQMF for a quality measure may reference multiple expressions within CQL to identify the various populations in the measure. In this case, the intervention may construct a proposal for a Chlamydia Screening:
define "ChlamydiaScreeningRequest": ProcedureRequest {
type: Code '442487003' from "SNOMED-CT"
display 'Screening for Chlamydia trachomatis (procedure)',
status: 'proposed'
// values for other elements of the request...
}
The containing artifact would then use this expression as the target of an action, evaluating the expression if the condition of the decision support rule is met, and returning the result as the proposal to the calling environment.
The previous examples of building a quality measure and a decision support artifact have so far demonstrated the ability to describe the logic involved using the same underlying data model, as well as the same expression language. Now we can take that one step further and look at the use of CQL libraries to actually express the artifacts using the same logic, rather than just the same data model and language.
We start by identifying the aspects that are identical between the two:
With these in mind, we can create a new library, CMS153_Common, that will contain the common elements:
library CMS153_Common version '2'
using QUICK
valueset "Female Administrative Sex": 'urn:oid:2.16.840.1.113883.3.560.100.2'
...
context Patient
define "ConditionsIndicatingSexualActivity":
[Condition: "Other Female Reproductive Conditions"]
union [Condition: "Genital Herpes"]
union ...
define "LaboratoryTestsIndicatingSexualActivity":
[DiagnosticOrder: "Pregnancy Test"]
union [DiagnosticOrder: "Pap"]
union ...
define "ResultsPresentForChlamydiaScreening":
[DiagnosticReport: "Chlamydia Screening"] R where R.result is not null
Using this library, we can then rewrite the CQM to reference the common elements from the library:
library CMS153_CQM version '2'
using QUICK
include CMS153_Common version '2' called Common
parameter MeasurementPeriod default Interval[
@2013-01-01T00:00:00.0,
@2014-01-01T00:00:00.0
)
context Patient
define "Patient16To23AndFemale":
AgeInYearsAt(start of MeasurementPeriod) >= 16
and AgeInYearsAt(start of MeasurementPeriod) < 24
and Patient.gender in Common."Female Administrative Sex"
define "SexuallyActive":
exists (Common"ConditionsIndicatingSexualActivity" C
where Interval[C.onsetDateTime, C.abatementDate] overlaps MeasurementPeriod)
or exists (Common"LaboratoryTestsIndicatingSexualActivity" R
where R.issued during MeasurementPeriod)
define "InInitialPopulation":
Patient16To23AndFemale and SexuallyActive
define "InDenominator":
true
define "InNumerator":
exists (Common"ResultsPresentForChlamydiaScreening" S
where S.issued during MeasurementPeriod)
Note: The keyword called was chosen to avoid confusion with the keyword as, which is used for type-casting. We also don't use as for aliasing like many SQL dialects do, for the same reason. We mean called here in the sense that the library is "called a name" within this context, not that we intend to "call it by this name".
And similarly for the CDS artifact:
library CMS153_CDS version '2'
using QUICK
include CMS153_Common version '2' called Common
valueset "Reason for not performing Chlamydia Screening": 'TBD'
context Patient
define "Patient16To23AndFemale":
AgeInYears() >= 16 and AgeInYears() < 24
and Patient.gender in Common."Female Administrative Sex"
define "SexuallyActive":
exists (Common"ConditionsIndicatingSexualActivity")
or exists (Common"LaboratoryTestsIndicatingSexualActivity")
define "NoScreening":
not exists (Common"ResultsPresentForChlamydiaScreening" S
where S.issued during Interval[Today() - 1 years, Today()])
and not exists ([ProcedureRequest: Common"Chlamydia Screening"] R
where R.orderedOn same day or after Today()
define "NeedScreening": Patient16To23AndFemale and SexuallyActive and NoScreening
In addition to sharing between quality measures and clinical decision support artifacts, the use of common libraries will allow the same logic to be shared by multiple quality measures or decision support artifacts. For example, a set of artifacts for measurement and improvement of the treatment of diabetes could all use a common library that provides base definitions for determining when a patient is part of the population of interest.